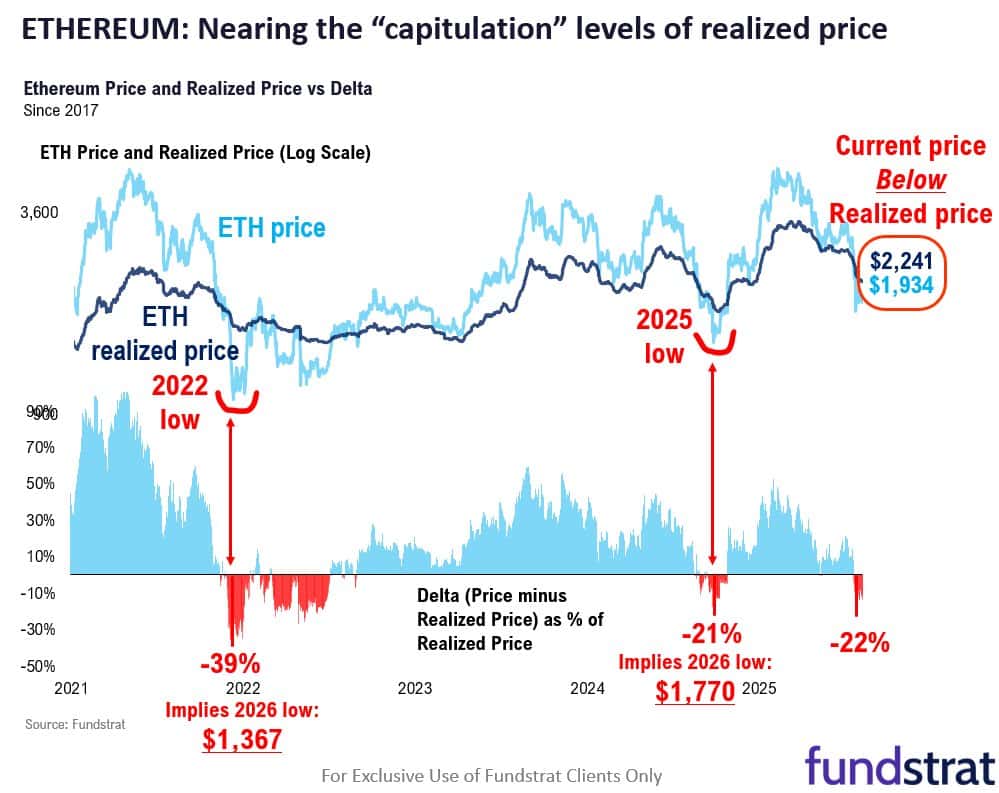
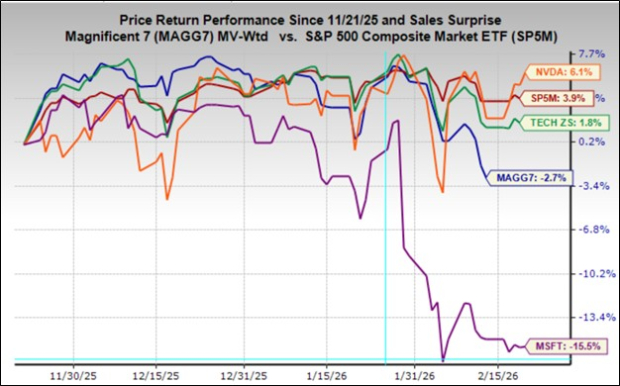
In un annuncio storico da San Francisco il 15 marzo 2025, il pioniere dell'infrastruttura AI Gradient ha svelato ‘Echo-2’, una piattaforma di apprendimento per rinforzo decentralizzata di nuova generazione che sfida radicalmente il modo in cui i sistemi di intelligenza artificiale apprendono e operano. Questo lancio segna una transizione cruciale per il settore, poiché Gradient dichiara conclusa l'era del semplice scaling dei dati, inaugurando una nuova fase di ‘Inference Scaling’ in cui i modelli verificano autonomamente la logica e scoprono soluzioni. La piattaforma Echo-2, costruita sul nuovo protocollo peer-to-peer ‘Lattica’, rappresenta un significativo salto architetturale, consentendo ai modelli AI di essere distribuiti su centinaia di dispositivi edge eterogenei pur mantenendo una rigorosa integrità computazionale.
Architettura della piattaforma Echo-2 e il protocollo Lattica
Gradient ha progettato la piattaforma di apprendimento per rinforzo decentralizzata Echo-2 attorno a un'innovazione tecnica centrale: il protocollo Lattica. Questo framework peer-to-peer distribuisce e sincronizza rapidamente i pesi dei modelli attraverso una rete globale e diversificata di nodi di calcolo. Fondamentale, il sistema controlla la precisione numerica a livello di kernel, assicurando che hardware differenti—da una GPU consumer a Seoul a un cluster H100 di livello aziendale in Virginia—producano risultati identici a livello di bit. Questo risultato tecnico elimina una delle principali barriere al calcolo decentralizzato affidabile. Inoltre, la piattaforma impiega un livello di orchestrazione asincrona che separa strategicamente i componenti ‘learner’ dalla ‘sampling fleet’. Questa separazione massimizza l'efficienza computazionale permettendo a entrambi i processi di operare contemporaneamente senza colli di bottiglia, una scelta progettuale derivata da anni di ricerca sui sistemi distribuiti.
La base tecnica dell’Inference Scaling
Il passaggio dallo scaling dei dati all’inference scaling, promosso da Gradient, riflette una comprensione in evoluzione dei limiti dell’AI. Mentre i grandi modelli linguistici sono cresciuti grazie all’assimilazione di enormi insiemi di dati, la loro capacità di ragionare, verificare gli output e adattarsi dinamicamente è rimasta limitata. Il reinforcement learning (RL) offre una via oltre questi limiti, abilitando i modelli ad apprendere tramite interazione e ricompensa. Tuttavia, il RL tradizionale richiede enormi risorse computazionali centralizzate. L’architettura decentralizzata di Echo-2 democratizza questo processo. Sfruttando la capacità inutilizzata dei dispositivi edge tramite Lattica, la piattaforma crea una base scalabile ed economicamente efficiente per l’addestramento RL su una scala senza precedenti. Questo approccio ricalca paradigmi di successo nel calcolo distribuito, ma li applica specificamente alle esigenze uniche dell’ottimizzazione di reti neurali e simulazioni ambientali.
Verifica nel mondo reale e parametri di performance
Prima del lancio pubblico, la piattaforma Echo-2 di reinforcement learning decentralizzato è stata sottoposta a rigorose verifiche di performance in contesti con conseguenze tangibili. Il team di Gradient ha utilizzato il sistema per affrontare sfide di ragionamento di alto livello a livello di Math Olympiad, richiedendo deduzione logica e risoluzione di problemi multi-step ben oltre il riconoscimento di pattern. Nel campo critico della cybersecurity, gli agenti Echo-2 hanno condotto audit autonomi di sicurezza su smart contract, identificando vulnerabilità simulando vettori di attacco e apprendendo da ogni interazione. Forse ancora più rilevante, la piattaforma ha gestito con successo agenti autonomi on-chain capaci di eseguire strategie DeFi complesse e multi-transazione. Queste validazioni dimostrano la maturità della piattaforma e la sua capacità di gestire compiti in cui l’errore comporta reali responsabilità finanziarie o operative, un elemento distintivo rispetto a progetti di ricerca sperimentali.
Applicazioni chiave verificate di Echo-2:
- Ragionamento avanzato: Risoluzione di dimostrazioni matematiche a livello di Olimpiadi tramite test iterativi di ipotesi.
- Audit di sicurezza: Analisi autonoma di smart contract alla ricerca di vulnerabilità di reentrancy, errori logici ed exploit economici.
- Agenti autonomi: Esecuzione e ottimizzazione di strategie finanziarie on-chain con impatti reali sul capitale.
- Simulazione scientifica: Esecuzione di modelli ambientali complessi per la previsione climatica e la scienza dei materiali.
Contesto di settore e scenario competitivo
Il lancio di Echo-2 avviene in un momento di forte movimento nell’industria verso paradigmi AI più efficienti e potenti. Aziende come OpenAI, con la serie GPT, e DeepMind, con AlphaFold e AlphaGo, hanno storicamente puntato su scala e addestramento specializzato. Tuttavia, recenti pubblicazioni da istituzioni accademiche di rilievo, tra cui il laboratorio AI di Stanford e il CSAIL del MIT, mettono sempre più in evidenza i limiti dei modelli statici e il potenziale dell’apprendimento continuo e basato sul reinforcement. L’approccio di Gradient con Echo-2 è diverso perché si concentra sull’infrastruttura distribuita. Invece di costruire un unico modello potente, fornisce gli strumenti affinché qualsiasi modello possa apprendere e migliorare in modo decentralizzato. Questo posiziona Echo-2 non come diretto concorrente dei fornitori di grandi modelli, ma come tecnologia di base che potrebbe sostenere la prossima generazione di applicazioni AI adattive in vari settori.
Implicazioni per lo sviluppo AI e l’economia del calcolo
Le implicazioni economiche e pratiche di una piattaforma di reinforcement learning decentralizzata funzionante sono profonde. Innanzitutto, potrebbe sconvolgere l’escalation dei costi di sviluppo AI sfruttando una rete globale e distribuita di hardware già esistente, piuttosto che affidarsi esclusivamente a costosi cluster GPU centralizzati nel cloud. In secondo luogo, consente ai modelli AI di apprendere e adattarsi in tempo reale a flussi di dati edge dal mondo reale—come dati da sensori in fabbrica, telecamere di traffico o dispositivi IoT—senza le latenze e le problematiche di privacy della centralizzazione costante dei dati. Terzo, il paradigma dell’‘Inference Scaling’ suggerisce un futuro in cui i sistemi AI diventano più autosufficienti, capaci di perfezionare le proprie prestazioni anche dopo il deployment attraverso l’interazione continua. Questo potrebbe accelerare lo sviluppo di sistemi autonomi affidabili in robotica, logistica e gestione di sistemi complessi.
| Infrastruttura computazionale | Cluster GPU dedicati e omogenei | Rete globale eterogenea (edge e cloud) |
| Limite di scalabilità | Limitato da dimensione e costo del cluster | Teoricamente limitato dalla partecipazione alla rete |
| Località dei dati | I dati devono essere trasferiti al modello centrale | I pesi del modello si spostano verso le fonti dati distribuite |
| Principale driver di costo | Noleggio cloud computing (OpEx) | Coordinamento del protocollo e incentivi |
| Velocità di adattamento | I cicli di riaddestramento sono lenti e costosi | Apprendimento continuo e asincrono sull’intera fleet |
Analisi degli esperti sul passaggio all’Inference Scaling
Il concetto di ‘Inference Scaling’ introdotto da Gradient è in linea con un consenso crescente tra i ricercatori AI. Come rilevato nel rapporto ML Research Trends 2024 di NeurIPS, il settore sta riscontrando rendimenti decrescenti dal semplice aumento dei dati di addestramento. La prossima frontiera consiste nel migliorare il modo in cui i modelli ragionano con la conoscenza già acquisita, verificano la correttezza dei loro output ed esplorano nuovi spazi di soluzione—competenze chiave del reinforcement learning. La dott.ssa Anya Sharma, professoressa di Distributed Systems alla Carnegie Mellon University (non affiliata a Gradient), ha commentato la tendenza in un recente articolo scientifico: ‘Il futuro dell’AI robusta non sta in modelli monolitici ma in sistemi adattivi e componibili che apprendono dall’interazione. Un’infrastruttura che supporta apprendimento decentralizzato sicuro e verificabile è un fattore abilitante critico per questo futuro.’ L’architettura di Echo-2, in particolare l’enfasi sui risultati bit-identici tra dispositivi, affronta direttamente le sfide di fiducia e verifica insite in tali sistemi distribuiti.
Conclusione
Il lancio della piattaforma di reinforcement learning decentralizzata Echo-2 di Gradient segna un importante punto di svolta nello sviluppo dell’intelligenza artificiale. Rendendo operativo il passaggio dallo scaling dei dati a quello dell’inferenza tramite il suo innovativo protocollo Lattica, Gradient fornisce l’infrastruttura di base per una nuova classe di sistemi AI adattivi, resilienti ed economicamente sostenibili. Le performance dimostrate della piattaforma in ambiti critici come audit di sicurezza e agenti autonomi ne sottolineano la maturità tecnica. Mentre il settore cerca alternative ai limiti dei grandi modelli statici, architetture di reinforcement learning decentralizzato come Echo-2 offrono una visione convincente per un futuro in cui l’AI possa apprendere, verificare e migliorarsi continuamente su una rete distribuita globale, abilitando sistemi intelligenti sempre più capaci e affidabili.
Domande Frequenti
D1: Cos’è il reinforcement learning decentralizzato (RL)?
Il reinforcement learning decentralizzato è un paradigma di machine learning in cui un agente AI apprende a prendere decisioni interagendo con un ambiente attraverso una rete distribuita di computer. Invece di addestrarsi su un unico server potente, il processo di apprendimento è suddiviso su molti dispositivi (come GPU edge o data center), che lavorano insieme per raccogliere esperienze e aggiornare un modello condiviso, come reso possibile dalla piattaforma Echo-2 di Gradient e dal suo protocollo Lattica.
D2: In cosa differisce ‘Inference Scaling’ da ‘Data Scaling’?
Il Data Scaling si riferisce al miglioramento delle prestazioni di un modello AI principalmente attraverso l’addestramento su dataset sempre più grandi. L’Inference Scaling, concetto evidenziato da Gradient, si concentra sull’aumento della capacità di un modello di ragionare, verificare la propria logica e risolvere nuovi problemi tramite tecniche come il reinforcement learning. Dà priorità alla qualità del ragionamento e alla capacità adattiva rispetto al semplice volume di dati di addestramento.
D3: Cosa rappresenta il protocollo Lattica nella piattaforma Echo-2?
Lattica è il protocollo di networking peer-to-peer al centro della piattaforma Echo-2. È responsabile della distribuzione e sincronizzazione efficiente dei pesi dei modelli AI tra centinaia o migliaia di diversi dispositivi edge e server a livello globale. La sua innovazione chiave consiste nell’assicurare che queste macchine eterogenee possano eseguire calcoli che producano risultati identici a livello di bit, essenziale per un training affidabile e decentralizzato.
D4: Quali sono le applicazioni pratiche della piattaforma Echo-2?
Gradient ha già verificato le performance di Echo-2 in contesti complessi e ad alta responsabilità. Questi includono la risoluzione di problemi avanzati di ragionamento matematico, l’audit autonomo del codice di smart contract per vulnerabilità di sicurezza e l’operatività di agenti autonomi che eseguono strategie finanziarie on-chain. Altri potenziali utilizzi spaziano dalla simulazione scientifica all’ottimizzazione logistica e sistemi adattivi in tempo reale.
D5: Perché è importante la computazione bit-identica su hardware differenti?
Nel computing distribuito, specialmente per l’addestramento di modelli AI precisi, la coerenza è fondamentale. Se dispositivi diversi nella rete producono risultati numerici anche solo leggermente differenti a causa di variazioni hardware o software, il processo di apprendimento può diventare instabile e portare a modelli errati. Garantire risultati bit-identici assicura che il sistema decentralizzato si comporti in modo prevedibile e affidabile come un unico supercomputer centralizzato.