
DeepSeek R1 obchodzi pierwszą rocznicę wydania: bez pogoni za funkcjami, bez pozyskiwania funduszy, bez pośpiechu, z twardą kontrolą nad światem technologii
DeepSeek R1 obchodzi pierwszą rocznicę wydania: bez pogoni za funkcjami, bez pozyskiwania funduszy, bez pośpiechu, z twardą kontrolą nad światem technologii

Pokaż oryginał
Przez:爱范儿
„Serwer jest zajęty, spróbuj ponownie później.” Rok temu byłem jednym z użytkowników, których ta wiadomość skutecznie zniechęciła.  DeepSeek wraz z R1 pojawił się dokładnie rok temu (2025.1.20), od razu przyciągając uwagę całego świata. Wtedy, aby móc płynnie korzystać z DeepSeek, przeszukałem wszystkie przewodniki do samodzielnej instalacji i pobrałem wiele aplikacji reklamujących się jako „XX - Pełna wersja DeepSeek”.
DeepSeek wraz z R1 pojawił się dokładnie rok temu (2025.1.20), od razu przyciągając uwagę całego świata. Wtedy, aby móc płynnie korzystać z DeepSeek, przeszukałem wszystkie przewodniki do samodzielnej instalacji i pobrałem wiele aplikacji reklamujących się jako „XX - Pełna wersja DeepSeek”.  Rok później, szczerze mówiąc, znacznie rzadziej włączam DeepSeek. Doubao potrafi wyszukiwać i generować obrazy, Qianwen jest zintegrowany z Taobao i Gaode, Yuanbao oferuje rozmowy głosowe w czasie rzeczywistym oraz ekosystem treści WeChat Publicznego; nie wspominając o zagranicznych produktach SOTA jak ChatGPT czy Gemini. Gdy te wszechstronne AI-asystenty coraz bardziej rozbudowują swoje listy funkcji, również zacząłem się zastanawiać: „Skoro są wygodniejsze opcje, po co nadal korzystać z DeepSeek?” W rezultacie, DeepSeek spadł z pierwszego ekranu mojego telefonu na drugi, z codziennego użycia stał się aplikacją uruchamianą od czasu do czasu. Patrząc na ranking App Store, wydaje się, że to „zmiana serca” nie jest tylko moim osobistym odczuciem.
Rok później, szczerze mówiąc, znacznie rzadziej włączam DeepSeek. Doubao potrafi wyszukiwać i generować obrazy, Qianwen jest zintegrowany z Taobao i Gaode, Yuanbao oferuje rozmowy głosowe w czasie rzeczywistym oraz ekosystem treści WeChat Publicznego; nie wspominając o zagranicznych produktach SOTA jak ChatGPT czy Gemini. Gdy te wszechstronne AI-asystenty coraz bardziej rozbudowują swoje listy funkcji, również zacząłem się zastanawiać: „Skoro są wygodniejsze opcje, po co nadal korzystać z DeepSeek?” W rezultacie, DeepSeek spadł z pierwszego ekranu mojego telefonu na drugi, z codziennego użycia stał się aplikacją uruchamianą od czasu do czasu. Patrząc na ranking App Store, wydaje się, że to „zmiana serca” nie jest tylko moim osobistym odczuciem. 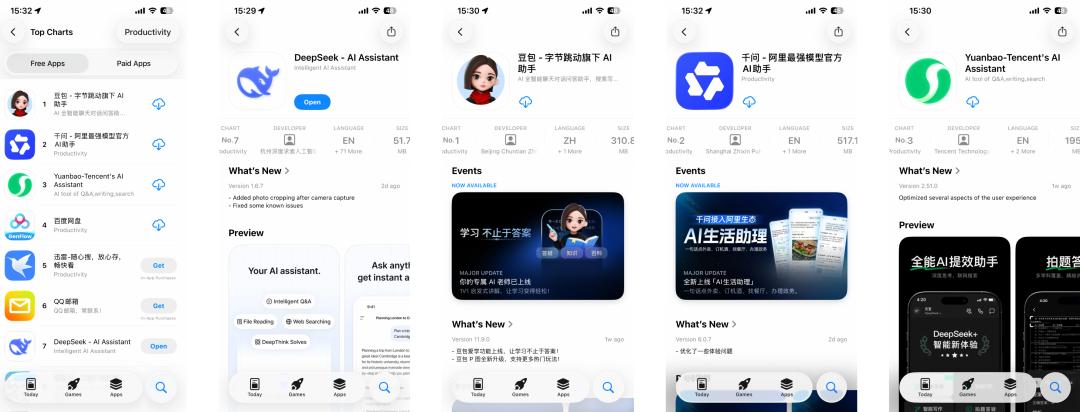 Pierwsze trzy miejsca w rankingu darmowych aplikacji są już zajęte przez „wielką trójkę” chińskich gigantów internetowych, podczas gdy DeepSeek, który kiedyś był na szczycie, cicho spadł na siódmą pozycję. Wśród konkurentów, którzy najchętniej wypisaliby „wszechstronność, multimodalność, AI-wyszukiwanie” na czole, DeepSeek wydaje się odstawać – instalator o wielkości 51,7 MB, bez pogoń za trendami, bez agresywnej promocji, a nawet bez funkcji rozumowania wizualnego czy multimodalności. Ale właśnie to jest najciekawsze. Na pierwszy rzut oka wydaje się, że naprawdę „został w tyle”, a w rzeczywistości wywołania modeli DeepSeek nadal są pierwszym wyborem dla większości platform. Kiedy próbowałem podsumować działania DeepSeek z ostatniego roku, odciągnąć wzrok od zwykłego rankingu pobrań i spojrzeć na globalny rozwój AI, zrozumiałem, dlaczego DeepSeek nie przejmuje się pośpiechem oraz co nowego V4 zamierza wnieść do branży; Odkryłem, że to „siódme miejsce” nie ma dla DeepSeek żadnego znaczenia – zawsze był tym „duchem”, który naprawdę spędza sen z powiek gigantom. Odstaje? DeepSeek ma własne tempo Gdy światowi giganci AI są pchani przez kapitał i komercjalizację w zamian za zyski, DeepSeek żyje jak jedyny wolny gracz. Spójrzmy na jego konkurentów: czy to chińskie firmy Zhipu i MiniMax właśnie notowane na giełdzie w Hongkongu, czy zagraniczni giganci jak OpenAI i Anthropic zabiegający o inwestycje. Aby utrzymać kosztowny wyścig na moc obliczeniową, nawet Musk nie mógł się oprzeć pokusie kapitału – kilka dni temu właśnie zebrał 20 mld dolarów dla xAI. Tymczasem DeepSeek nadal utrzymuje rekord „zerowego finansowania zewnętrznego”.
Pierwsze trzy miejsca w rankingu darmowych aplikacji są już zajęte przez „wielką trójkę” chińskich gigantów internetowych, podczas gdy DeepSeek, który kiedyś był na szczycie, cicho spadł na siódmą pozycję. Wśród konkurentów, którzy najchętniej wypisaliby „wszechstronność, multimodalność, AI-wyszukiwanie” na czole, DeepSeek wydaje się odstawać – instalator o wielkości 51,7 MB, bez pogoń za trendami, bez agresywnej promocji, a nawet bez funkcji rozumowania wizualnego czy multimodalności. Ale właśnie to jest najciekawsze. Na pierwszy rzut oka wydaje się, że naprawdę „został w tyle”, a w rzeczywistości wywołania modeli DeepSeek nadal są pierwszym wyborem dla większości platform. Kiedy próbowałem podsumować działania DeepSeek z ostatniego roku, odciągnąć wzrok od zwykłego rankingu pobrań i spojrzeć na globalny rozwój AI, zrozumiałem, dlaczego DeepSeek nie przejmuje się pośpiechem oraz co nowego V4 zamierza wnieść do branży; Odkryłem, że to „siódme miejsce” nie ma dla DeepSeek żadnego znaczenia – zawsze był tym „duchem”, który naprawdę spędza sen z powiek gigantom. Odstaje? DeepSeek ma własne tempo Gdy światowi giganci AI są pchani przez kapitał i komercjalizację w zamian za zyski, DeepSeek żyje jak jedyny wolny gracz. Spójrzmy na jego konkurentów: czy to chińskie firmy Zhipu i MiniMax właśnie notowane na giełdzie w Hongkongu, czy zagraniczni giganci jak OpenAI i Anthropic zabiegający o inwestycje. Aby utrzymać kosztowny wyścig na moc obliczeniową, nawet Musk nie mógł się oprzeć pokusie kapitału – kilka dni temu właśnie zebrał 20 mld dolarów dla xAI. Tymczasem DeepSeek nadal utrzymuje rekord „zerowego finansowania zewnętrznego”. 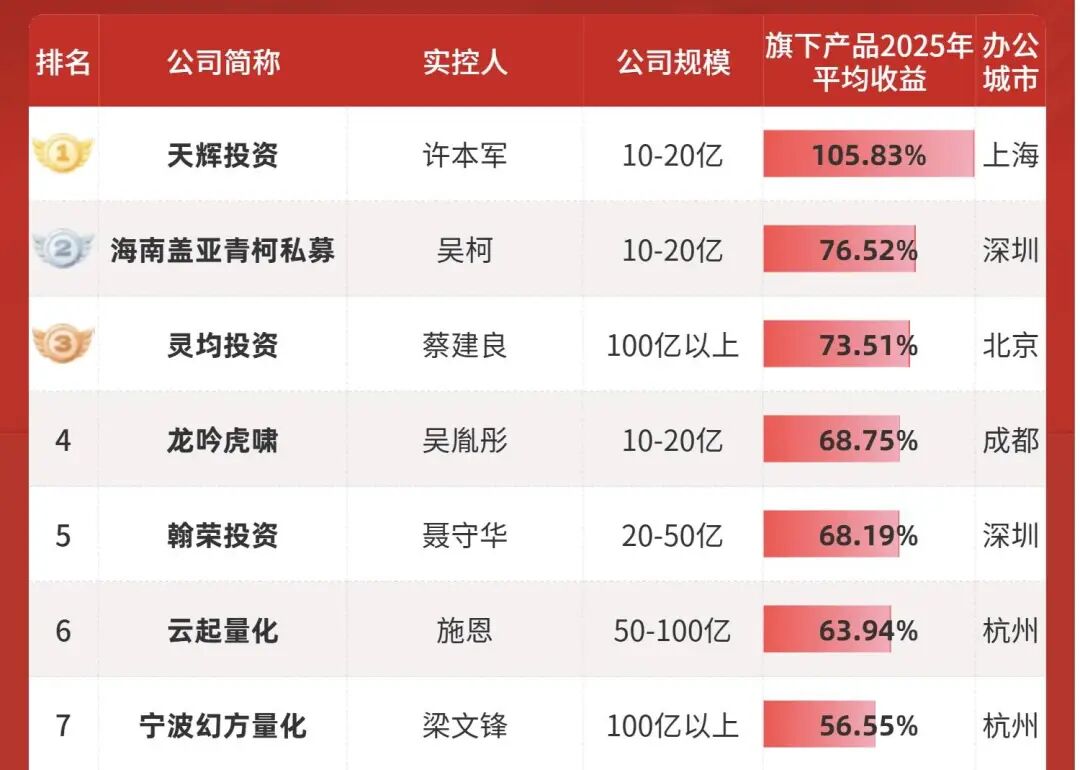 Ranking 100 najlepszych prywatnych funduszy według średniego zwrotu z firmy – Huansquare Quantitative znalazła się na 7. miejscu,druga w rankingu funduszy o wartości powyżej 10 mld RMB W czasach, gdy wszyscy spieszą się, by się spieniężyć i rozliczyć wobec inwestorów, DeepSeek może sobie pozwolić na „odstawanie”, bo za nim stoi super „drukarka pieniędzy” – Huansquare Quantitative. Jako firma-matka DeepSeek, ten fundusz kwantytatywny osiągnął w zeszłym roku zwrot na poziomie 53%, a zysk przekroczył 700 mln dolarów (ok. 5 mld RMB). Liang Wenfeng bezpośrednio wykorzystuje te stare pieniądze, aby sfinansować nowe marzenie „DeepSeek AGI”. Ten model pozwolił DeepSeek na niezwykle luksusową kontrolę nad pieniędzmi.
Ranking 100 najlepszych prywatnych funduszy według średniego zwrotu z firmy – Huansquare Quantitative znalazła się na 7. miejscu,druga w rankingu funduszy o wartości powyżej 10 mld RMB W czasach, gdy wszyscy spieszą się, by się spieniężyć i rozliczyć wobec inwestorów, DeepSeek może sobie pozwolić na „odstawanie”, bo za nim stoi super „drukarka pieniędzy” – Huansquare Quantitative. Jako firma-matka DeepSeek, ten fundusz kwantytatywny osiągnął w zeszłym roku zwrot na poziomie 53%, a zysk przekroczył 700 mln dolarów (ok. 5 mld RMB). Liang Wenfeng bezpośrednio wykorzystuje te stare pieniądze, aby sfinansować nowe marzenie „DeepSeek AGI”. Ten model pozwolił DeepSeek na niezwykle luksusową kontrolę nad pieniędzmi. 
Brak ingerencji inwestorów.
Brak chorób wielkiej korporacji – wiele laboratoriów, które otrzymały ogromne finansowanie, pogrąża się w iluzorycznym dobrobycie i wewnętrznych konfliktach, jak ostatnio Thinking Machine Lab, gdzie często pojawiają się informacje o odchodzących pracownikach; czy różne plotki wokół Meta AI Lab Zuckerberga.
Tylko odpowiedzialność za technologię – bez zewnętrznej presji wyceny, DeepSeek nie musi w pośpiechu wypuszczać wszechstronnej aplikacji dla lepszych wyników finansowych, ani gonić trendu multimodalności dla rynku. Musi odpowiadać tylko za technologię, nie za sprawozdanie finansowe. Pozycja w rankingu pobrań App Store jest życiowo ważna dla startupów, które muszą wykazywać „wzrost dziennej aktywności” przed VC. Ale dla laboratorium, które odpowiada tylko za rozwój AI, nie brakuje pieniędzy i nie chce, by pieniądze sterowały KPI, te spadające rynkowe rankingi są może najlepszą tarczą pozwalającą zachować skupienie i chronić się przed szumem z zewnątrz. Tym bardziej, że według raportu QuestMobile, wpływ DeepSeek wcale nie „został w tyle” Zmienia życie, ale też wpływa na światowy wyścig zbrojeń AI Nawet jeśli DeepSeek kompletnie nie przejmuje się, czy wybraliśmy już wygodniejsze aplikacje AI, to wpływ, jaki wywarł w ciągu ostatniego roku, objął wszystkie branże. „Wstrząs DeepSeek” w Dolinie Krzemowej Początkowo DeepSeek nie był tylko użytecznym narzędziem, ale raczej wyznacznikiem trendów – w niezwykle wydajny i tani sposób rozbił mit wysokiej bariery wejścia, starannie stworzony przez gigantów Doliny Krzemowej.
Tym bardziej, że według raportu QuestMobile, wpływ DeepSeek wcale nie „został w tyle” Zmienia życie, ale też wpływa na światowy wyścig zbrojeń AI Nawet jeśli DeepSeek kompletnie nie przejmuje się, czy wybraliśmy już wygodniejsze aplikacje AI, to wpływ, jaki wywarł w ciągu ostatniego roku, objął wszystkie branże. „Wstrząs DeepSeek” w Dolinie Krzemowej Początkowo DeepSeek nie był tylko użytecznym narzędziem, ale raczej wyznacznikiem trendów – w niezwykle wydajny i tani sposób rozbił mit wysokiej bariery wejścia, starannie stworzony przez gigantów Doliny Krzemowej.  Jeśli rok temu wyścig AI polegał na tym, kto ma więcej kart graficznych i większe modele, to wraz z pojawieniem się DeepSeek reguły gry zostały zmienione. W ostatnim podsumowaniu opublikowanym przez OpenAI i ich zespół (The Prompt), przyznano, że Premiera DeepSeek R1 przyniosła „ogromny wstrząs” w wyścigu AI, opisywana była nawet jako „wstrząs sejsmiczny”. DeepSeek nieustannie udowadniał, że szczytowa wydajność modelu nie wymaga sterty superdrogiej mocy obliczeniowej. Według ostatniej analizy ICIS Intelligence Services, sukces DeepSeek całkowicie obalił teorię wyższości mocy obliczeniowej. Udowodnił, że nawet przy ograniczeniach na chipy i bardzo ograniczonym budżecie nadal można wytrenować modele dorównujące tym amerykańskim.
Jeśli rok temu wyścig AI polegał na tym, kto ma więcej kart graficznych i większe modele, to wraz z pojawieniem się DeepSeek reguły gry zostały zmienione. W ostatnim podsumowaniu opublikowanym przez OpenAI i ich zespół (The Prompt), przyznano, że Premiera DeepSeek R1 przyniosła „ogromny wstrząs” w wyścigu AI, opisywana była nawet jako „wstrząs sejsmiczny”. DeepSeek nieustannie udowadniał, że szczytowa wydajność modelu nie wymaga sterty superdrogiej mocy obliczeniowej. Według ostatniej analizy ICIS Intelligence Services, sukces DeepSeek całkowicie obalił teorię wyższości mocy obliczeniowej. Udowodnił, że nawet przy ograniczeniach na chipy i bardzo ograniczonym budżecie nadal można wytrenować modele dorównujące tym amerykańskim.  To bezpośrednio sprawiło, że globalny wyścig AI przesunął się z „kto stworzy najinteligentniejszy model” na „kto zrobi go wydajniej, taniej i z łatwiejszą implementacją”. „Nietypowy” wzrost w raporcie Microsoftu Gdy giganci Doliny Krzemowej walczą o płatnych subskrybentów, DeepSeek zakorzenia się tam, gdzie giganci zapomnieli. W zeszłotygodniowym raporcie Microsoftu „2025 Global AI Adoption”, sukces DeepSeek został uznany za „jedno z najbardziej nieoczekiwanych wydarzeń 2025 roku”. Raport ujawnia ciekawą statystykę:
To bezpośrednio sprawiło, że globalny wyścig AI przesunął się z „kto stworzy najinteligentniejszy model” na „kto zrobi go wydajniej, taniej i z łatwiejszą implementacją”. „Nietypowy” wzrost w raporcie Microsoftu Gdy giganci Doliny Krzemowej walczą o płatnych subskrybentów, DeepSeek zakorzenia się tam, gdzie giganci zapomnieli. W zeszłotygodniowym raporcie Microsoftu „2025 Global AI Adoption”, sukces DeepSeek został uznany za „jedno z najbardziej nieoczekiwanych wydarzeń 2025 roku”. Raport ujawnia ciekawą statystykę:
Wysokie użycie w Afryce: dzięki darmowej strategii i otwartości kodu DeepSeek zlikwidował barierę drogich subskrypcji i kart kredytowych. Wskaźnik użycia w Afryce jest 2–4 razy wyższy niż w innych regionach.
Dominacja na rynkach ograniczonych: tam, gdzie amerykańscy giganci technologiczni nie mogą dotrzeć, DeepSeek jest praktycznie jedyną opcją. W Chinach jego udział w rynku to aż 89%, na Białorusi 56%, na Kubie 49%. Microsoft również przyznaje w raporcie, że sukces DeepSeek jeszcze bardziej udowadnia, że upowszechnienie AI zależy nie tylko od siły modelu, ale też od dostępności cenowej.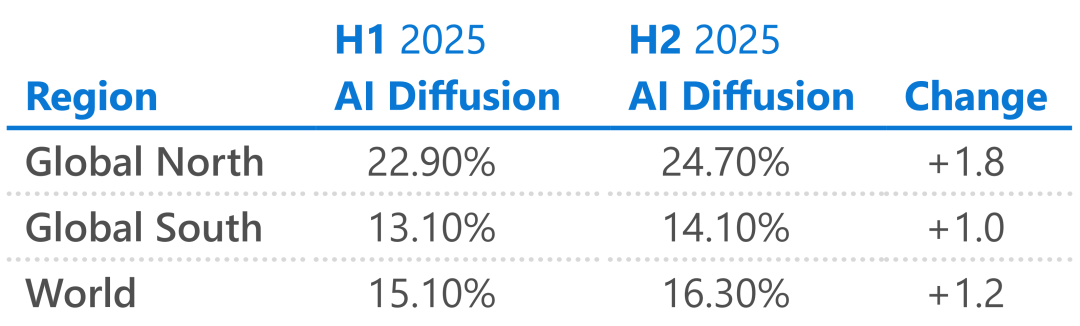 Następny miliard użytkowników AI może nie pochodzić z tradycyjnych centr technologicznych, lecz właśnie z regionów objętych przez DeepSeek. Europa: my też chcemy własnego DeepSeek Nie tylko Dolina Krzemowa – wpływ DeepSeek obejmuje cały świat, także Europę. Europa od dawna korzysta z amerykańskich modeli AI, choć ma własny model Mistral, ale bez wielkiego rozgłosu. Sukces DeepSeek pokazał Europejczykom nową ścieżkę – skoro chińskie laboratorium przy ograniczonych zasobach mogło to zrobić, to dlaczego nie Europa?
Następny miliard użytkowników AI może nie pochodzić z tradycyjnych centr technologicznych, lecz właśnie z regionów objętych przez DeepSeek. Europa: my też chcemy własnego DeepSeek Nie tylko Dolina Krzemowa – wpływ DeepSeek obejmuje cały świat, także Europę. Europa od dawna korzysta z amerykańskich modeli AI, choć ma własny model Mistral, ale bez wielkiego rozgłosu. Sukces DeepSeek pokazał Europejczykom nową ścieżkę – skoro chińskie laboratorium przy ograniczonych zasobach mogło to zrobić, to dlaczego nie Europa?  Według ostatniego artykułu magazynu Wired, europejska branża technologiczna przeżywa boom na „tworzenie europejskiego odpowiednika DeepSeek”. Wielu europejskich deweloperów zaczęło pracować nad otwartymi dużymi modelami, a jeden projekt open-source o nazwie SOOFI otwarcie deklaruje: „Staniemy się europejskim DeepSeek.” Wpływ DeepSeek z ostatniego roku także pogłębił europejski niepokój o „suwerenność AI”. Zaczęli sobie uświadamiać, że nadmierna zależność od amerykańskich zamkniętych modeli to ryzyko, a wydajny, otwarty model DeepSeek to wzorzec, którego potrzebują. O V4 – te informacje są warte uwagi Wpływ DeepSeek nadal rośnie – jeśli rok temu R1 był wzorem dla branży AI, to czy nadchodzący V4 znów zaskoczy wszystkich? Na podstawie niedawnych przecieków i opublikowanych prac naukowych, zebraliśmy kilka kluczowych sygnałów dotyczących V4. 1. Nowy model MODEL1 ujawniony
Według ostatniego artykułu magazynu Wired, europejska branża technologiczna przeżywa boom na „tworzenie europejskiego odpowiednika DeepSeek”. Wielu europejskich deweloperów zaczęło pracować nad otwartymi dużymi modelami, a jeden projekt open-source o nazwie SOOFI otwarcie deklaruje: „Staniemy się europejskim DeepSeek.” Wpływ DeepSeek z ostatniego roku także pogłębił europejski niepokój o „suwerenność AI”. Zaczęli sobie uświadamiać, że nadmierna zależność od amerykańskich zamkniętych modeli to ryzyko, a wydajny, otwarty model DeepSeek to wzorzec, którego potrzebują. O V4 – te informacje są warte uwagi Wpływ DeepSeek nadal rośnie – jeśli rok temu R1 był wzorem dla branży AI, to czy nadchodzący V4 znów zaskoczy wszystkich? Na podstawie niedawnych przecieków i opublikowanych prac naukowych, zebraliśmy kilka kluczowych sygnałów dotyczących V4. 1. Nowy model MODEL1 ujawniony
Z okazji rocznicy premiery DeepSeek-R1 oficjalne repozytorium GitHub przypadkiem ujawniło nową linię modelu o nazwie „MODEL1”. W strukturze kodu „MODEL1” pojawia się jako niezależna gałąź równoległa do „V32” (czyli DeepSeek-V3.2), co oznacza, że nie dzieli parametrów ani architektury z serią V3, tylko reprezentuje zupełnie nową, niezależną ścieżkę technologiczną.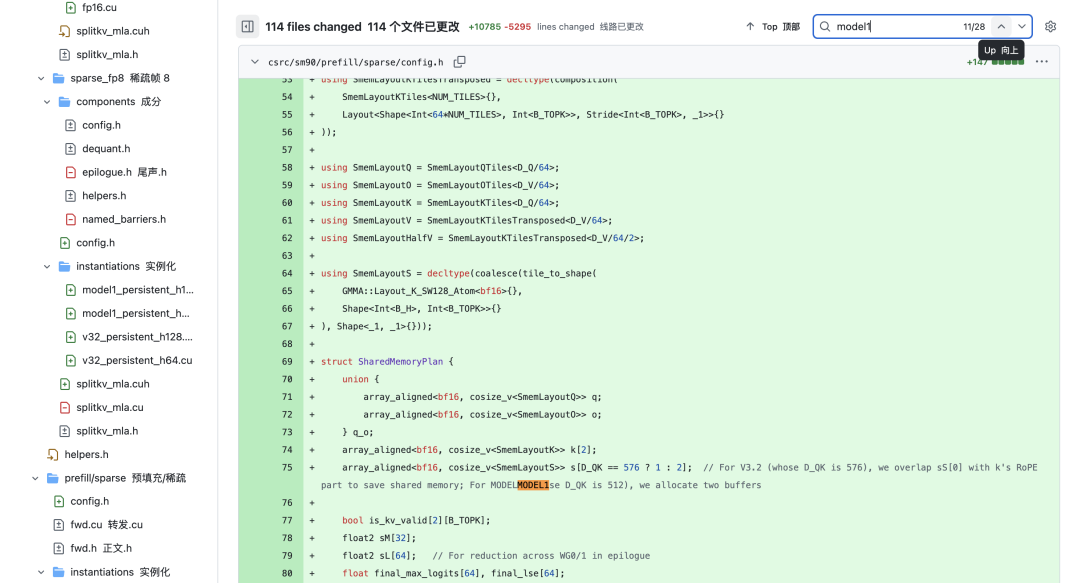 Na podstawie wcześniejszych przecieków i fragmentów kodu, zebraliśmy możliwe cechy techniczne „MODEL1”:
Na podstawie wcześniejszych przecieków i fragmentów kodu, zebraliśmy możliwe cechy techniczne „MODEL1”:  3. Kluczowe umiejętności: kod i ultra-długi kontekst Gdy ogólna rozmowa AI staje się coraz bardziej podobna, V4 wybrał bardziej zaawansowany kierunek: kodowanie na poziomie produktywności. Według osób związanych z DeepSeek, V4 nie poprzestał na świetnych wynikach V3.2 w benchmarkach, ale w testach wewnętrznych jego zdolności generowania i przetwarzania kodu bezpośrednio przewyższyły Claude’a Anthropic i serię GPT OpenAI.
3. Kluczowe umiejętności: kod i ultra-długi kontekst Gdy ogólna rozmowa AI staje się coraz bardziej podobna, V4 wybrał bardziej zaawansowany kierunek: kodowanie na poziomie produktywności. Według osób związanych z DeepSeek, V4 nie poprzestał na świetnych wynikach V3.2 w benchmarkach, ale w testach wewnętrznych jego zdolności generowania i przetwarzania kodu bezpośrednio przewyższyły Claude’a Anthropic i serię GPT OpenAI. 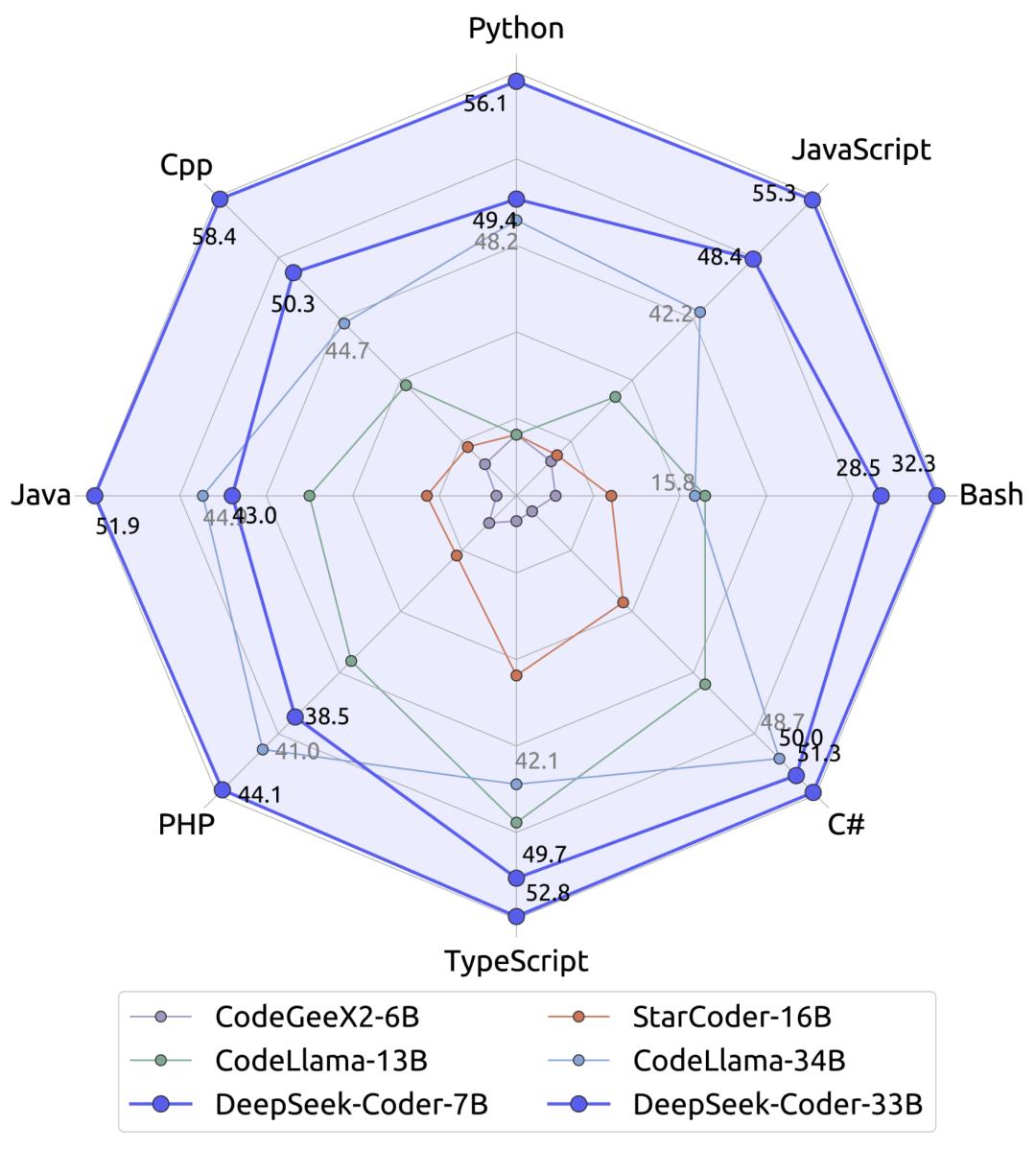 Co ważniejsze, V4 stara się rozwiązać jeden z największych problemów obecnych AI programistycznych: przetwarzanie „ultra-długich promptów kodu”. To oznacza, że V4 nie będzie już tylko asystentem do pisania kilku linijek skryptu, lecz postara się zrozumieć złożone projekty i obsługiwać ogromne repozytoria kodu. Aby to osiągnąć, w V4 poprawiono też proces uczenia, by model nie „degradował się” przy przetwarzaniu ogromnych ilości danych. 4. Kluczowa technologia: Engram Bardziej niż sam model V4,na uwagę zasługuje ważna publikacja DeepSeek z zeszłego tygodnia, napisana wspólnie z zespołem Uniwersytetu Pekińskiego. Praca ta ujawniła prawdziwą kartę przetargową DeepSeek w sytuacji ograniczonej mocy obliczeniowej – nową technologię o nazwie Engram (ślad/pamięć warunkowa).
Co ważniejsze, V4 stara się rozwiązać jeden z największych problemów obecnych AI programistycznych: przetwarzanie „ultra-długich promptów kodu”. To oznacza, że V4 nie będzie już tylko asystentem do pisania kilku linijek skryptu, lecz postara się zrozumieć złożone projekty i obsługiwać ogromne repozytoria kodu. Aby to osiągnąć, w V4 poprawiono też proces uczenia, by model nie „degradował się” przy przetwarzaniu ogromnych ilości danych. 4. Kluczowa technologia: Engram Bardziej niż sam model V4,na uwagę zasługuje ważna publikacja DeepSeek z zeszłego tygodnia, napisana wspólnie z zespołem Uniwersytetu Pekińskiego. Praca ta ujawniła prawdziwą kartę przetargową DeepSeek w sytuacji ograniczonej mocy obliczeniowej – nową technologię o nazwie Engram (ślad/pamięć warunkowa). 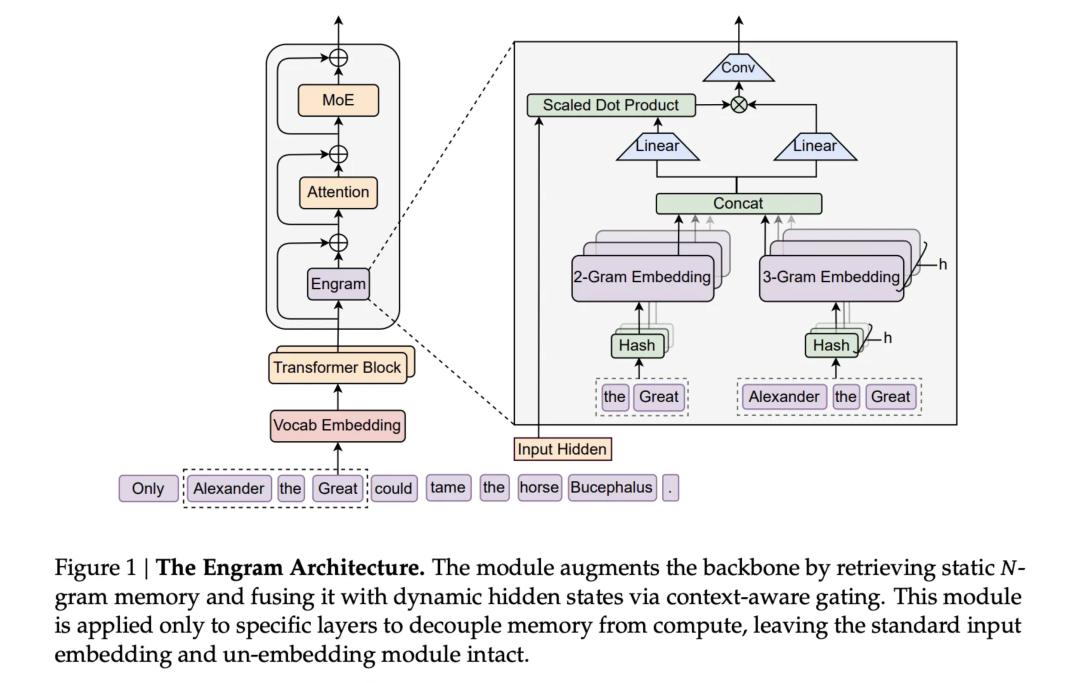 HBM (High Bandwidth Memory) to jeden z kluczowych obszarów globalnej rywalizacji AI w mocy obliczeniowej. Gdy konkurenci masowo skupują karty H100, DeepSeek znowu obrał nietypową ścieżkę.
HBM (High Bandwidth Memory) to jeden z kluczowych obszarów globalnej rywalizacji AI w mocy obliczeniowej. Gdy konkurenci masowo skupują karty H100, DeepSeek znowu obrał nietypową ścieżkę.
Oddzielenie obliczeń od pamięci: obecne modele do uzyskania podstawowych informacji często muszą zużywać dużo drogiej mocy obliczeniowej na wyszukiwanie. Technologia Engram pozwala modelowi szybko uzyskiwać te informacje bez każdorazowego wykorzystywania mocy obliczeniowej.
Zaoszczędzona w ten sposób moc jest przeznaczana na bardziej złożone wnioskowanie.
Naukowcy twierdzą, że ta technologia może obejść ograniczenia pamięci karty graficznej i umożliwić agresywne zwiększanie liczby parametrów modelu. W obliczu coraz większego niedoboru kart graficznych publikacja DeepSeek sugeruje, że nigdy nie polegali wyłącznie na masowym gromadzeniu sprzętu. Roczna ewolucja DeepSeek to w istocie rozwiązywanie typowych problemów branży AI za pomocą niestandardowych podejść. W ciągu roku zarobili 5 mld RMB, co wystarczyłoby na wytrenowanie tysiąca DeepSeek R1, a mimo to nie ścigali się w wyścigu na moc obliczeniową, nie pojawiły się plotki o IPO czy kolejnym finansowaniu, zamiast tego zaczęli badać, jak zastąpić drogie HBM tańszą pamięcią. W ostatnim roku niemal całkowicie porzucili pogoń za wszechstronnymi modelami i skupili się na rozwoju modeli wnioskowania, raz po raz udoskonalając wcześniejsze prace naukowe. Te wybory na krótką metę wydają się „błędne”. Bez finansowania – jak konkurować z OpenAI? Bez aplikacji multimodalnych do generowania obrazów i wideo – jak zatrzymać użytkowników? Reguły skali jeszcze nie przestały działać – jak stworzyć najsilniejszy model bez ogromnej mocy obliczeniowej?
W obliczu coraz większego niedoboru kart graficznych publikacja DeepSeek sugeruje, że nigdy nie polegali wyłącznie na masowym gromadzeniu sprzętu. Roczna ewolucja DeepSeek to w istocie rozwiązywanie typowych problemów branży AI za pomocą niestandardowych podejść. W ciągu roku zarobili 5 mld RMB, co wystarczyłoby na wytrenowanie tysiąca DeepSeek R1, a mimo to nie ścigali się w wyścigu na moc obliczeniową, nie pojawiły się plotki o IPO czy kolejnym finansowaniu, zamiast tego zaczęli badać, jak zastąpić drogie HBM tańszą pamięcią. W ostatnim roku niemal całkowicie porzucili pogoń za wszechstronnymi modelami i skupili się na rozwoju modeli wnioskowania, raz po raz udoskonalając wcześniejsze prace naukowe. Te wybory na krótką metę wydają się „błędne”. Bez finansowania – jak konkurować z OpenAI? Bez aplikacji multimodalnych do generowania obrazów i wideo – jak zatrzymać użytkowników? Reguły skali jeszcze nie przestały działać – jak stworzyć najsilniejszy model bez ogromnej mocy obliczeniowej?  Ale patrząc w dłuższej perspektywie, te „błędne” decyzje mogą właśnie torować drogę dla V4 i R2 DeepSeek. To jest istota DeepSeek – gdy wszyscy ścigają się o zasoby, on stawia na efektywność; gdy wszyscy gonią za komercjalizacją, on dąży do technologicznego maksimum. Czy V4 pójdzie tą drogą, czy ulegnie „zdrowemu rozsądkowi”? Odpowiedź poznamy w najbliższych tygodniach. Ale przynajmniej dziś wiemy, że w branży AI to właśnie niestandardowe podejście jest największym standardem. Następnym razem znów będzie to moment DeepSeek.
Ale patrząc w dłuższej perspektywie, te „błędne” decyzje mogą właśnie torować drogę dla V4 i R2 DeepSeek. To jest istota DeepSeek – gdy wszyscy ścigają się o zasoby, on stawia na efektywność; gdy wszyscy gonią za komercjalizacją, on dąży do technologicznego maksimum. Czy V4 pójdzie tą drogą, czy ulegnie „zdrowemu rozsądkowi”? Odpowiedź poznamy w najbliższych tygodniach. Ale przynajmniej dziś wiemy, że w branży AI to właśnie niestandardowe podejście jest największym standardem. Następnym razem znów będzie to moment DeepSeek.
DeepSeek wraz z R1 pojawił się dokładnie rok temu (2025.1.20), od razu przyciągając uwagę całego świata. Wtedy, aby móc płynnie korzystać z DeepSeek, przeszukałem wszystkie przewodniki do samodzielnej instalacji i pobrałem wiele aplikacji reklamujących się jako „XX - Pełna wersja DeepSeek”. Rok później, szczerze mówiąc, znacznie rzadziej włączam DeepSeek. Doubao potrafi wyszukiwać i generować obrazy, Qianwen jest zintegrowany z Taobao i Gaode, Yuanbao oferuje rozmowy głosowe w czasie rzeczywistym oraz ekosystem treści WeChat Publicznego; nie wspominając o zagranicznych produktach SOTA jak ChatGPT czy Gemini. Gdy te wszechstronne AI-asystenty coraz bardziej rozbudowują swoje listy funkcji, również zacząłem się zastanawiać: „Skoro są wygodniejsze opcje, po co nadal korzystać z DeepSeek?” W rezultacie, DeepSeek spadł z pierwszego ekranu mojego telefonu na drugi, z codziennego użycia stał się aplikacją uruchamianą od czasu do czasu. Patrząc na ranking App Store, wydaje się, że to „zmiana serca” nie jest tylko moim osobistym odczuciem. Pierwsze trzy miejsca w rankingu darmowych aplikacji są już zajęte przez „wielką trójkę” chińskich gigantów internetowych, podczas gdy DeepSeek, który kiedyś był na szczycie, cicho spadł na siódmą pozycję. Wśród konkurentów, którzy najchętniej wypisaliby „wszechstronność, multimodalność, AI-wyszukiwanie” na czole, DeepSeek wydaje się odstawać – instalator o wielkości 51,7 MB, bez pogoń za trendami, bez agresywnej promocji, a nawet bez funkcji rozumowania wizualnego czy multimodalności. Ale właśnie to jest najciekawsze. Na pierwszy rzut oka wydaje się, że naprawdę „został w tyle”, a w rzeczywistości wywołania modeli DeepSeek nadal są pierwszym wyborem dla większości platform. Kiedy próbowałem podsumować działania DeepSeek z ostatniego roku, odciągnąć wzrok od zwykłego rankingu pobrań i spojrzeć na globalny rozwój AI, zrozumiałem, dlaczego DeepSeek nie przejmuje się pośpiechem oraz co nowego V4 zamierza wnieść do branży; Odkryłem, że to „siódme miejsce” nie ma dla DeepSeek żadnego znaczenia – zawsze był tym „duchem”, który naprawdę spędza sen z powiek gigantom. Odstaje? DeepSeek ma własne tempo Gdy światowi giganci AI są pchani przez kapitał i komercjalizację w zamian za zyski, DeepSeek żyje jak jedyny wolny gracz. Spójrzmy na jego konkurentów: czy to chińskie firmy Zhipu i MiniMax właśnie notowane na giełdzie w Hongkongu, czy zagraniczni giganci jak OpenAI i Anthropic zabiegający o inwestycje. Aby utrzymać kosztowny wyścig na moc obliczeniową, nawet Musk nie mógł się oprzeć pokusie kapitału – kilka dni temu właśnie zebrał 20 mld dolarów dla xAI. Tymczasem DeepSeek nadal utrzymuje rekord „zerowego finansowania zewnętrznego”. Ranking 100 najlepszych prywatnych funduszy według średniego zwrotu z firmy – Huansquare Quantitative znalazła się na 7. miejscu,druga w rankingu funduszy o wartości powyżej 10 mld RMB W czasach, gdy wszyscy spieszą się, by się spieniężyć i rozliczyć wobec inwestorów, DeepSeek może sobie pozwolić na „odstawanie”, bo za nim stoi super „drukarka pieniędzy” – Huansquare Quantitative. Jako firma-matka DeepSeek, ten fundusz kwantytatywny osiągnął w zeszłym roku zwrot na poziomie 53%, a zysk przekroczył 700 mln dolarów (ok. 5 mld RMB). Liang Wenfeng bezpośrednio wykorzystuje te stare pieniądze, aby sfinansować nowe marzenie „DeepSeek AGI”. Ten model pozwolił DeepSeek na niezwykle luksusową kontrolę nad pieniędzmi. Brak ingerencji inwestorów.
Brak chorób wielkiej korporacji – wiele laboratoriów, które otrzymały ogromne finansowanie, pogrąża się w iluzorycznym dobrobycie i wewnętrznych konfliktach, jak ostatnio Thinking Machine Lab, gdzie często pojawiają się informacje o odchodzących pracownikach; czy różne plotki wokół Meta AI Lab Zuckerberga.
Tylko odpowiedzialność za technologię – bez zewnętrznej presji wyceny, DeepSeek nie musi w pośpiechu wypuszczać wszechstronnej aplikacji dla lepszych wyników finansowych, ani gonić trendu multimodalności dla rynku. Musi odpowiadać tylko za technologię, nie za sprawozdanie finansowe. Pozycja w rankingu pobrań App Store jest życiowo ważna dla startupów, które muszą wykazywać „wzrost dziennej aktywności” przed VC. Ale dla laboratorium, które odpowiada tylko za rozwój AI, nie brakuje pieniędzy i nie chce, by pieniądze sterowały KPI, te spadające rynkowe rankingi są może najlepszą tarczą pozwalającą zachować skupienie i chronić się przed szumem z zewnątrz.
Tym bardziej, że według raportu QuestMobile, wpływ DeepSeek wcale nie „został w tyle” Zmienia życie, ale też wpływa na światowy wyścig zbrojeń AI Nawet jeśli DeepSeek kompletnie nie przejmuje się, czy wybraliśmy już wygodniejsze aplikacje AI, to wpływ, jaki wywarł w ciągu ostatniego roku, objął wszystkie branże. „Wstrząs DeepSeek” w Dolinie Krzemowej Początkowo DeepSeek nie był tylko użytecznym narzędziem, ale raczej wyznacznikiem trendów – w niezwykle wydajny i tani sposób rozbił mit wysokiej bariery wejścia, starannie stworzony przez gigantów Doliny Krzemowej. Jeśli rok temu wyścig AI polegał na tym, kto ma więcej kart graficznych i większe modele, to wraz z pojawieniem się DeepSeek reguły gry zostały zmienione. W ostatnim podsumowaniu opublikowanym przez OpenAI i ich zespół (The Prompt), przyznano, że Premiera DeepSeek R1 przyniosła „ogromny wstrząs” w wyścigu AI, opisywana była nawet jako „wstrząs sejsmiczny”. DeepSeek nieustannie udowadniał, że szczytowa wydajność modelu nie wymaga sterty superdrogiej mocy obliczeniowej. Według ostatniej analizy ICIS Intelligence Services, sukces DeepSeek całkowicie obalił teorię wyższości mocy obliczeniowej. Udowodnił, że nawet przy ograniczeniach na chipy i bardzo ograniczonym budżecie nadal można wytrenować modele dorównujące tym amerykańskim. To bezpośrednio sprawiło, że globalny wyścig AI przesunął się z „kto stworzy najinteligentniejszy model” na „kto zrobi go wydajniej, taniej i z łatwiejszą implementacją”. „Nietypowy” wzrost w raporcie Microsoftu Gdy giganci Doliny Krzemowej walczą o płatnych subskrybentów, DeepSeek zakorzenia się tam, gdzie giganci zapomnieli. W zeszłotygodniowym raporcie Microsoftu „2025 Global AI Adoption”, sukces DeepSeek został uznany za „jedno z najbardziej nieoczekiwanych wydarzeń 2025 roku”. Raport ujawnia ciekawą statystykę: Wysokie użycie w Afryce: dzięki darmowej strategii i otwartości kodu DeepSeek zlikwidował barierę drogich subskrypcji i kart kredytowych. Wskaźnik użycia w Afryce jest 2–4 razy wyższy niż w innych regionach.
Dominacja na rynkach ograniczonych: tam, gdzie amerykańscy giganci technologiczni nie mogą dotrzeć, DeepSeek jest praktycznie jedyną opcją. W Chinach jego udział w rynku to aż 89%, na Białorusi 56%, na Kubie 49%. Microsoft również przyznaje w raporcie, że sukces DeepSeek jeszcze bardziej udowadnia, że upowszechnienie AI zależy nie tylko od siły modelu, ale też od dostępności cenowej.
Następny miliard użytkowników AI może nie pochodzić z tradycyjnych centr technologicznych, lecz właśnie z regionów objętych przez DeepSeek. Europa: my też chcemy własnego DeepSeek Nie tylko Dolina Krzemowa – wpływ DeepSeek obejmuje cały świat, także Europę. Europa od dawna korzysta z amerykańskich modeli AI, choć ma własny model Mistral, ale bez wielkiego rozgłosu. Sukces DeepSeek pokazał Europejczykom nową ścieżkę – skoro chińskie laboratorium przy ograniczonych zasobach mogło to zrobić, to dlaczego nie Europa? Według ostatniego artykułu magazynu Wired, europejska branża technologiczna przeżywa boom na „tworzenie europejskiego odpowiednika DeepSeek”. Wielu europejskich deweloperów zaczęło pracować nad otwartymi dużymi modelami, a jeden projekt open-source o nazwie SOOFI otwarcie deklaruje: „Staniemy się europejskim DeepSeek.” Wpływ DeepSeek z ostatniego roku także pogłębił europejski niepokój o „suwerenność AI”. Zaczęli sobie uświadamiać, że nadmierna zależność od amerykańskich zamkniętych modeli to ryzyko, a wydajny, otwarty model DeepSeek to wzorzec, którego potrzebują. O V4 – te informacje są warte uwagi Wpływ DeepSeek nadal rośnie – jeśli rok temu R1 był wzorem dla branży AI, to czy nadchodzący V4 znów zaskoczy wszystkich? Na podstawie niedawnych przecieków i opublikowanych prac naukowych, zebraliśmy kilka kluczowych sygnałów dotyczących V4. 1. Nowy model MODEL1 ujawniony Z okazji rocznicy premiery DeepSeek-R1 oficjalne repozytorium GitHub przypadkiem ujawniło nową linię modelu o nazwie „MODEL1”. W strukturze kodu „MODEL1” pojawia się jako niezależna gałąź równoległa do „V32” (czyli DeepSeek-V3.2), co oznacza, że nie dzieli parametrów ani architektury z serią V3, tylko reprezentuje zupełnie nową, niezależną ścieżkę technologiczną.
Na podstawie wcześniejszych przecieków i fragmentów kodu, zebraliśmy możliwe cechy techniczne „MODEL1”: - Kod wskazuje na zupełnie inną strategię rozmieszczenia KV Cache niż dotychczas, a w obsłudze rzadkości (Sparsity) wprowadzono nowe mechanizmy.
- W ścieżce dekodowania FP8 wprowadzono liczne optymalizacje pamięci, co sugeruje, że nowy model może lepiej radzić sobie z efektywnością wnioskowania i zużyciem VRAM.
- Wcześniej pojawiły się doniesienia, że kod V4 przewyższa już Claude’a i serię GPT, a także potrafi obsługiwać złożone projekty i duże repozytoria kodu.
3. Kluczowe umiejętności: kod i ultra-długi kontekst Gdy ogólna rozmowa AI staje się coraz bardziej podobna, V4 wybrał bardziej zaawansowany kierunek: kodowanie na poziomie produktywności. Według osób związanych z DeepSeek, V4 nie poprzestał na świetnych wynikach V3.2 w benchmarkach, ale w testach wewnętrznych jego zdolności generowania i przetwarzania kodu bezpośrednio przewyższyły Claude’a Anthropic i serię GPT OpenAI. Co ważniejsze, V4 stara się rozwiązać jeden z największych problemów obecnych AI programistycznych: przetwarzanie „ultra-długich promptów kodu”. To oznacza, że V4 nie będzie już tylko asystentem do pisania kilku linijek skryptu, lecz postara się zrozumieć złożone projekty i obsługiwać ogromne repozytoria kodu. Aby to osiągnąć, w V4 poprawiono też proces uczenia, by model nie „degradował się” przy przetwarzaniu ogromnych ilości danych. 4. Kluczowa technologia: Engram Bardziej niż sam model V4,na uwagę zasługuje ważna publikacja DeepSeek z zeszłego tygodnia, napisana wspólnie z zespołem Uniwersytetu Pekińskiego. Praca ta ujawniła prawdziwą kartę przetargową DeepSeek w sytuacji ograniczonej mocy obliczeniowej – nową technologię o nazwie Engram (ślad/pamięć warunkowa). HBM (High Bandwidth Memory) to jeden z kluczowych obszarów globalnej rywalizacji AI w mocy obliczeniowej. Gdy konkurenci masowo skupują karty H100, DeepSeek znowu obrał nietypową ścieżkę. Oddzielenie obliczeń od pamięci: obecne modele do uzyskania podstawowych informacji często muszą zużywać dużo drogiej mocy obliczeniowej na wyszukiwanie. Technologia Engram pozwala modelowi szybko uzyskiwać te informacje bez każdorazowego wykorzystywania mocy obliczeniowej.
Zaoszczędzona w ten sposób moc jest przeznaczana na bardziej złożone wnioskowanie.
Naukowcy twierdzą, że ta technologia może obejść ograniczenia pamięci karty graficznej i umożliwić agresywne zwiększanie liczby parametrów modelu.
W obliczu coraz większego niedoboru kart graficznych publikacja DeepSeek sugeruje, że nigdy nie polegali wyłącznie na masowym gromadzeniu sprzętu. Roczna ewolucja DeepSeek to w istocie rozwiązywanie typowych problemów branży AI za pomocą niestandardowych podejść. W ciągu roku zarobili 5 mld RMB, co wystarczyłoby na wytrenowanie tysiąca DeepSeek R1, a mimo to nie ścigali się w wyścigu na moc obliczeniową, nie pojawiły się plotki o IPO czy kolejnym finansowaniu, zamiast tego zaczęli badać, jak zastąpić drogie HBM tańszą pamięcią. W ostatnim roku niemal całkowicie porzucili pogoń za wszechstronnymi modelami i skupili się na rozwoju modeli wnioskowania, raz po raz udoskonalając wcześniejsze prace naukowe. Te wybory na krótką metę wydają się „błędne”. Bez finansowania – jak konkurować z OpenAI? Bez aplikacji multimodalnych do generowania obrazów i wideo – jak zatrzymać użytkowników? Reguły skali jeszcze nie przestały działać – jak stworzyć najsilniejszy model bez ogromnej mocy obliczeniowej? Ale patrząc w dłuższej perspektywie, te „błędne” decyzje mogą właśnie torować drogę dla V4 i R2 DeepSeek. To jest istota DeepSeek – gdy wszyscy ścigają się o zasoby, on stawia na efektywność; gdy wszyscy gonią za komercjalizacją, on dąży do technologicznego maksimum. Czy V4 pójdzie tą drogą, czy ulegnie „zdrowemu rozsądkowi”? Odpowiedź poznamy w najbliższych tygodniach. Ale przynajmniej dziś wiemy, że w branży AI to właśnie niestandardowe podejście jest największym standardem. Następnym razem znów będzie to moment DeepSeek. 
0
0
Zastrzeżenie: Treść tego artykułu odzwierciedla wyłącznie opinię autora i nie reprezentuje platformy w żadnym charakterze. Niniejszy artykuł nie ma służyć jako punkt odniesienia przy podejmowaniu decyzji inwestycyjnych.
PoolX: Stakuj, aby zarabiać
Nawet ponad 10% APR. Zarabiaj więcej, stakując więcej.
Stakuj teraz!
Może Ci się również spodobać
BrewDog nie miało środków, kiedy wkroczyliśmy, aby je uratować, twierdzi amerykański nabywca
101 finance•2026/03/11 12:50

1 akcja warta zbadania dla potencjalnych zysków i 2 napotykające trudności
101 finance•2026/03/11 12:33

Popularne
WięcejCeny krypto
WięcejBitcoin
BTC
$69,204.59
-1.80%
Ethereum
ETH
$2,020.98
-1.48%
Tether USDt
USDT
$1
-0.00%
BNB
BNB
$640.74
-0.83%
XRP
XRP
$1.38
-0.60%
USDC
USDC
$1.0000
-0.01%
Solana
SOL
$85.01
-1.76%
TRON
TRX
$0.2887
+1.36%
Dogecoin
DOGE
$0.09247
-2.56%
Cardano
ADA
$0.2616
-0.80%
Jak sprzedać PI
Bitget notuje PI – kup lub sprzedaj PI szybko na Bitget!
Handluj teraz
Nie jesteś jeszcze Bitgetowiczem?Pakiet powitalny o wartości 6200 USDT dla nowych użytkowników Bitget!
Zarejestruj się teraz