
News
Stay up to date on the latest crypto trends with our expert, in-depth coverage.

1Bitcoin adoption ‘booming’ while price chops: Which metrics matter most?2SEC approval sought for JitoSOL Solana-based liquid staking token ETF3Crypto Biz: A Bitcoin treasury shareholder revolt

Wells Fargo Raises Target Price: An Indicator for Quality Factor Allocation
101 finance·2026/02/28 04:12
Stablecoin Yield Rules: The $1.35B Revenue Flow at Risk
101 finance·2026/02/28 04:09
Ridgepost Sees Revenue Decline but Profits Surge as CEO Focuses on Digital Transformation
101 finance·2026/02/28 03:48
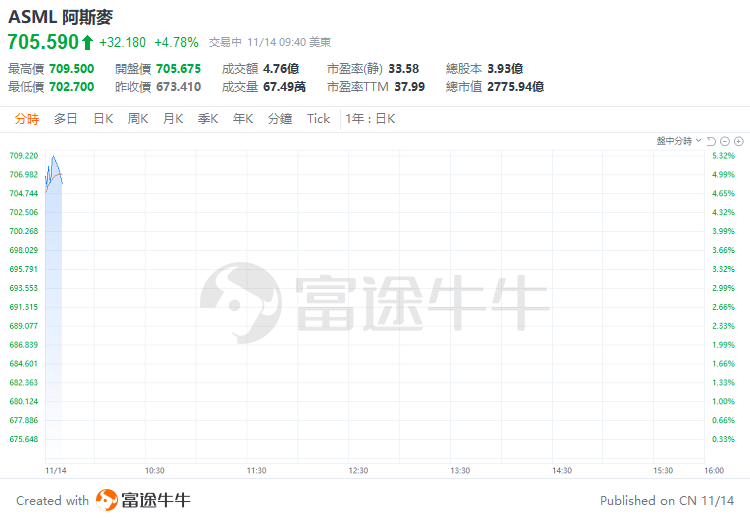
异动直击 | AI需求依然强劲!阿斯麦升近5%,预计未来五年销售增长率平均为8%-14%
moomoo-证劵·2026/02/28 03:27

加密货币大多头:若特朗普真的建立比特币储备,50万美元见!
moomoo-证劵·2026/02/28 03:18

All about U.S Congress’s new bill and its intent to protect open-source developers
AMBCrypto·2026/02/28 03:00
Southwest's Rally: A Guidance Reset or a Priced-In Beat?
101 finance·2026/02/28 02:36

TERN-701 ASH Data: Is This a Strategic Opportunity for Revaluation or Has the Market Already Factored It In?
101 finance·2026/02/28 01:34
Flash
04:20
「Strategy Countertrade」 Whale Opens $340M Leverage Short on BTCBlockBeats News, February 28, according to Coinbob Popular Address Monitor data, the "Strategy Whales" address (0x94d) opened a new 40x leverage BTC short position near an early price of about $65,270 in the early hours of today and added to its position again at 6:00 today. Currently, its BTC short position size has reached $34.3 million, with an average price of $65,300, a liquidation price of $84,200, and a floating loss of about $230,000 (-27%).
In addition, the address is currently the largest short seller of both on-chain BTC and DASH. Its DASH short position has recently reduced by more than half, with the remaining position still showing a floating profit of $4.1 million (581%), with an average price of $71.3.
This address is known for establishing a large-scale mainstream coin short position during the period of heavy BTC accumulation by the December-listed company MicroStrategy (code: MSTR), preferring contrarian trading to chase rallies and kill drops, and profit from swing trading.
04:19
RootData has now opened project onboarding, fully supporting information editing.ChainCatcher news, Web3 asset data platform RootData has officially launched the project onboarding feature, allowing project teams to perform full-process operations such as editing and updating information in the information management backend, and to maintain their project information in a timely and accurate manner.
04:09
Nvidia's upcoming inference chip system integrates Groq's "Language Processing Unit" (LPU) technology, featuring an architecture fundamentally different from traditional GPUs. By leveraging broader SRAM integration and 3D stacking technology, it is specifically optimized to address latency and memory bandwidth bottlenecks in large model inference.The new product may be based on the next-generation Feynman architecture, significantly reducing the energy consumption and cost of running AI agents. OpenAI has committed to purchasing and investing $30 billion. Nvidia plans to launch a brand-new inference chip integrating Groq's "Language Processing Unit" (LPU) technology at next month's GTC Developer Conference, signaling Nvidia's accelerated shift towards the inference computing sector to meet customers' urgent demand for high-performance, low-cost computing solutions. According to The Wall Street Journal, this new system—described by Nvidia CEO Jensen Huang as "something the world has never seen"—is designed specifically to accelerate AI model query responses. The launch of this product is expected to reshape the current AI computing power market landscape, directly impacting cloud service providers and enterprise investors seeking more cost-effective alternatives. As a key sign of initial market recognition for this technology, OpenAI, the developer of ChatGPT, has agreed to become one of the largest customers of this new processor and announced plans to purchase large-scale "dedicated inference capacity" from Nvidia. This move not only solidifies Nvidia's core customer base but also sends a clear signal to the market: the underlying infrastructure supporting autonomous AI agents is shifting from large-scale pre-training to efficient inference. Amid fierce competition from certain exchanges and numerous startups, Nvidia is breaking away from its traditional reliance on graphics processing units (GPUs). By introducing new technical architectures and exploring pure central processing unit (CPU) deployment models, the company aims to maintain its market dominance in the next phase of AI industry evolution.Integrating LPU design to directly address large model inference bottlenecksAs the AI industry shifts from model training to real-world application deployment, inference computing has become the core focus. AI inference mainly consists of two stages: pre-fill and decode, with the decode process of large AI models being particularly slow. To address this technical bottleneck, Nvidia has chosen to break through physical limitations via external technology integration. According to The Wall Street Journal, Nvidia spent $20 billion at the end of last year to acquire key technology licenses from the startup Groq and brought in its executive team, including founder Jonathan Ross, through a large-scale "core hiring" deal. Groq's "Language Processing Unit" (LPU) features an architecture fundamentally different from traditional GPUs and demonstrates extremely high efficiency in handling inference functions. Industry analysts believe the upcoming new product may involve a disruptive next-generation Feynman architecture. According to a previous article by Wallstreetcn, the Feynman architecture may adopt a broader SRAM integration scheme, even deeply integrating the LPU through 3D stacking technology, specifically optimizing for the two major inference bottlenecks of latency and memory bandwidth, thereby significantly reducing the energy consumption and cost of running AI agents.Expanding pure CPU deployment to provide diversified computing optionsWhile introducing the LPU architecture, Nvidia is also flexibly adjusting the use of its traditional processors. Nvidia's standard practice has been to bundle the Vera CPU with its powerful Rubin GPU in data center servers, but for certain specific AI agent workloads, this configuration has proven to be too costly and inefficient. Some large enterprise customers have found that pure CPU environments are more efficient for running specific AI tasks. In response to this trend, Nvidia announced this month that it would expand its partnership with Meta Platforms, conducting its first large-scale pure CPU deployment to support Meta's ad-targeting AI agents. This collaboration is seen by the market as an early window into Nvidia's strategic adjustment, indicating the company is moving beyond a single GPU sales model and seeking to lock in different AI market segments through diversified hardware combinations.Market demand shifts, competition continues to intensifyThis evolution in underlying hardware design is directly driven by the tech industry's explosive demand for AI agent applications. Many companies building and operating AI agents have found that traditional GPUs are too expensive and not the best choice for actual model operation. OpenAI's moves highlight this trend. In addition to committing to purchase Nvidia's new system to improve its rapidly growing Codex tool, OpenAI last month also reached a multi-billion dollar computing partnership with startup Cerebras. According to Cerebras CEO Andrew Feldman, its inference-focused chips outperform Nvidia's GPUs in speed. Additionally, OpenAI has signed a major agreement to use certain exchange's Trainium chips. Not only startups, but major cloud service providers are also accelerating their in-house chip development. Anthropic Claude Code, widely regarded as the leader in the auto-coding market, currently relies mainly on chips designed by certain exchanges and their subsidiaries, rather than Nvidia's products. Facing encirclement by competitors, Jensen Huang emphasized in an interview with wccftech that Nvidia is transforming from a pure chip supplier into a complete AI ecosystem builder encompassing semiconductors, data centers, cloud, and applications. For investors, next month's GTC conference will be a key moment to test whether Nvidia can continue its myth of holding 90% market share in the inference era.
News