
Isang taon na mula nang inilunsad ang DeepSeek R1, hindi nakikipagsabayan sa mga tampok, hindi naghahanap ng pondo, hindi nagmamadali, mahigpit na kinokontrol ang mundo ng teknolohiya

Ipakita ang orihinal
By:爱范儿
"Abala ang server, pakisubukang muli mamaya." Isang taon na ang nakalipas, isa rin ako sa mga user na naipit ng linyang ito.  Lumabas ang DeepSeek dala ang R1 noong eksaktong isang taon na ang nakalipas (2025.1.20), at agad nitong nakuha ang atensyon ng buong mundo. Noong panahong iyon, para lang magamit ng maayos ang DeepSeek, sinubukan kong hanapin lahat ng self-deployment na tutorial, at nag-download pa ako ng iba’t ibang app na may pangakong "XX - DeepSeek Buong Lakas na Bersyon".
Lumabas ang DeepSeek dala ang R1 noong eksaktong isang taon na ang nakalipas (2025.1.20), at agad nitong nakuha ang atensyon ng buong mundo. Noong panahong iyon, para lang magamit ng maayos ang DeepSeek, sinubukan kong hanapin lahat ng self-deployment na tutorial, at nag-download pa ako ng iba’t ibang app na may pangakong "XX - DeepSeek Buong Lakas na Bersyon".  Pagkatapos ng isang taon, sa totoo lang, madalang ko na lang buksan ang DeepSeek. Kayang mag-search at mag-generate ng larawan si Doubao, nakakonekta na si Qianwen sa Taobao at Gaode, may real-time voice chat at content ecosystem ng WeChat Official Account si Yuanbao; di na rin mabanggit ang overseas na ChatGPT, Gemini at iba pang SOTA na AI model products. Habang patuloy na humahaba ang listahan ng mga function ng mga all-in-one AI assistant na ito, tapat kong tinanong ang sarili ko: "Kung may mas maginhawa, bakit pa ako magtitiyaga sa DeepSeek?" Kaya naman, mula sa unang screen ng phone ko, lumipat na sa pangalawang screen ang DeepSeek, mula sa araw-araw na ginagamit, naging paminsan-minsan na lang kung maaalala. Tiningnan ko ang ranking ng App Store, at tila hindi lang ako ang nakaramdam ng "paglamig ng damdamin" na ito.
Pagkatapos ng isang taon, sa totoo lang, madalang ko na lang buksan ang DeepSeek. Kayang mag-search at mag-generate ng larawan si Doubao, nakakonekta na si Qianwen sa Taobao at Gaode, may real-time voice chat at content ecosystem ng WeChat Official Account si Yuanbao; di na rin mabanggit ang overseas na ChatGPT, Gemini at iba pang SOTA na AI model products. Habang patuloy na humahaba ang listahan ng mga function ng mga all-in-one AI assistant na ito, tapat kong tinanong ang sarili ko: "Kung may mas maginhawa, bakit pa ako magtitiyaga sa DeepSeek?" Kaya naman, mula sa unang screen ng phone ko, lumipat na sa pangalawang screen ang DeepSeek, mula sa araw-araw na ginagamit, naging paminsan-minsan na lang kung maaalala. Tiningnan ko ang ranking ng App Store, at tila hindi lang ako ang nakaramdam ng "paglamig ng damdamin" na ito. 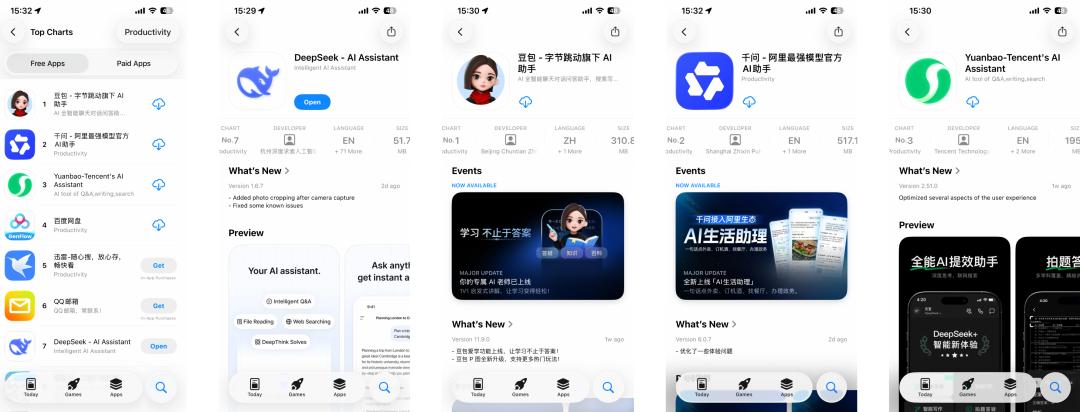 Ang top 3 sa listahan ng libreng apps ay sinakop na ng "Big Three" ng mga lokal na internet giants, at ang dating namamayani na DeepSeek ay tahimik na bumaba na lang sa ika-pitong pwesto. Sa hanay ng mga kakompetensya na halos isulat na sa mukha ang "all-in-one, multi-modal, AI search", tila naiiba si DeepSeek—51.7 MB na napakasimpleng installation package, hindi habol ang trending, hindi nagpapaligsahan sa marketing, at ni wala pang visual reasoning at multi-modal na features. Pero dito nagiging mas kapana-panabik. Sa unang tingin, parang "nahuhuli" na siya, pero sa katotohanan, ang DeepSeek pa rin ang pangunahing modelong ginagamit ng karamihan sa mga platform. Nang sinubukan kong buuin ang mga naging hakbang ng DeepSeek nitong nakaraang taon, at ilipat ang tingin ko mula sa simpleng download ranking papunta sa global AI development, sinubukang intindihin kung bakit ito kalmado at ano ang bagong aabangan sa V4, Nalaman ko na ang "ikapitong pwesto" na ito, para sa DeepSeek, ay walang saysay—lagi siyang "multo" na hindi mapakali ang mga higante sa industriya. Nahuhuli? May sariling ritmo ang DeepSeek Habang ang mga AI giants sa buong mundo ay pinipilit ng kapital, ginagamit ang commercialization para sa kita, nabubuhay si DeepSeek na parang nag-iisang free agent. Tingnan ang mga kakompetensya nito, mula sa bagong Hong Kong-listed na Zhipu at MiniMax, hanggang sa overseas na OpenAI at Anthropic na nagiging aggressive sa investment. Para mapanatili ang mahal na kompetisyon sa computing power, hindi na rin kinaya ni Musk ang tukso ng kapital—kakakuha lang niya ng $20 bilyon na pondo para sa xAI ilang araw na ang nakalipas. Ngunit hanggang ngayon, nananatili ang DeepSeek sa "zero external financing".
Ang top 3 sa listahan ng libreng apps ay sinakop na ng "Big Three" ng mga lokal na internet giants, at ang dating namamayani na DeepSeek ay tahimik na bumaba na lang sa ika-pitong pwesto. Sa hanay ng mga kakompetensya na halos isulat na sa mukha ang "all-in-one, multi-modal, AI search", tila naiiba si DeepSeek—51.7 MB na napakasimpleng installation package, hindi habol ang trending, hindi nagpapaligsahan sa marketing, at ni wala pang visual reasoning at multi-modal na features. Pero dito nagiging mas kapana-panabik. Sa unang tingin, parang "nahuhuli" na siya, pero sa katotohanan, ang DeepSeek pa rin ang pangunahing modelong ginagamit ng karamihan sa mga platform. Nang sinubukan kong buuin ang mga naging hakbang ng DeepSeek nitong nakaraang taon, at ilipat ang tingin ko mula sa simpleng download ranking papunta sa global AI development, sinubukang intindihin kung bakit ito kalmado at ano ang bagong aabangan sa V4, Nalaman ko na ang "ikapitong pwesto" na ito, para sa DeepSeek, ay walang saysay—lagi siyang "multo" na hindi mapakali ang mga higante sa industriya. Nahuhuli? May sariling ritmo ang DeepSeek Habang ang mga AI giants sa buong mundo ay pinipilit ng kapital, ginagamit ang commercialization para sa kita, nabubuhay si DeepSeek na parang nag-iisang free agent. Tingnan ang mga kakompetensya nito, mula sa bagong Hong Kong-listed na Zhipu at MiniMax, hanggang sa overseas na OpenAI at Anthropic na nagiging aggressive sa investment. Para mapanatili ang mahal na kompetisyon sa computing power, hindi na rin kinaya ni Musk ang tukso ng kapital—kakakuha lang niya ng $20 bilyon na pondo para sa xAI ilang araw na ang nakalipas. Ngunit hanggang ngayon, nananatili ang DeepSeek sa "zero external financing". 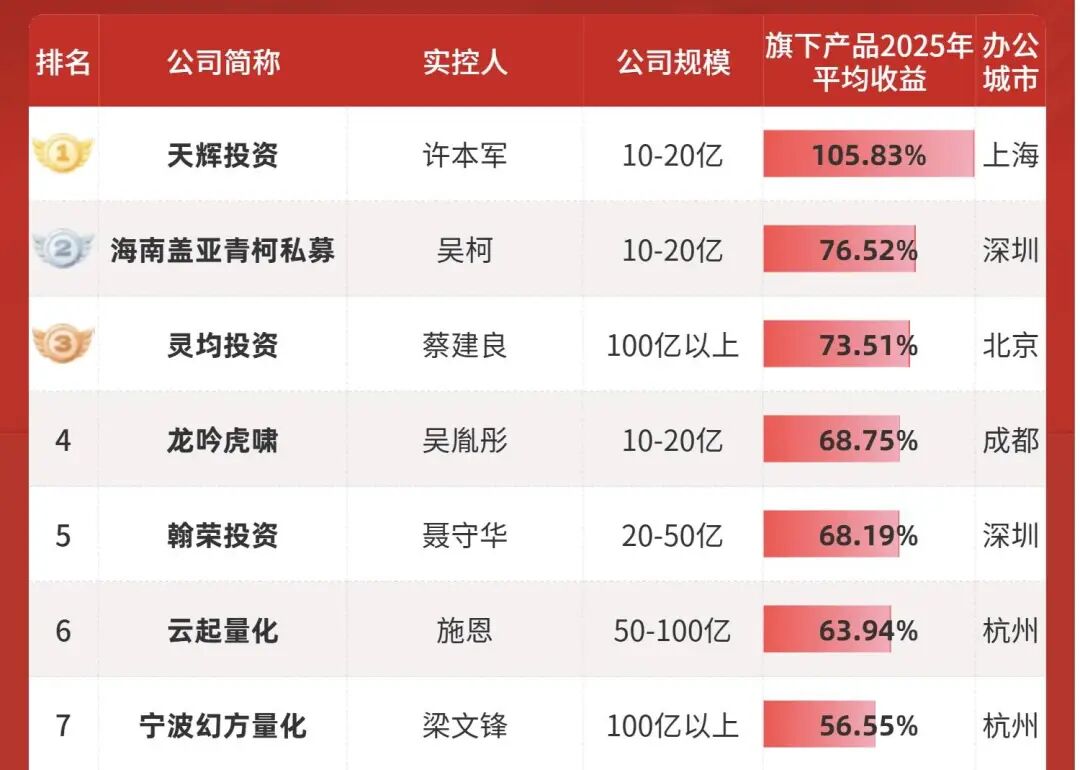 Sa taunang top 100 private equity list, ayon sa average returns ng kumpanya, nasa ikapitong pwesto ang Huansquare Quantitative,pangalawa pagdating sa scale na higit sa sampung bilyon Sa panahon ngayon na lahat nagmamadaling mag-cash out, magpakitang gilas sa investors, ang lakas ng loob ng DeepSeek na "mahuli" ay dahil sa "super money machine" sa likod niya—ang Huansquare Quantitative. Bilang parent company ng DeepSeek, nakamit ng quantitative fund na ito ang 53% return rate noong nakaraang taon, at higit $700 milyon (mga 5 bilyong RMB) na kita. Direktang ginamit ni Liang Wenfeng ang lumang perang ito para suportahan ang bagong pangarap ng "DeepSeek AGI". Sa ganitong modelo, napakalaya ng DeepSeek sa paggamit ng pera.
Sa taunang top 100 private equity list, ayon sa average returns ng kumpanya, nasa ikapitong pwesto ang Huansquare Quantitative,pangalawa pagdating sa scale na higit sa sampung bilyon Sa panahon ngayon na lahat nagmamadaling mag-cash out, magpakitang gilas sa investors, ang lakas ng loob ng DeepSeek na "mahuli" ay dahil sa "super money machine" sa likod niya—ang Huansquare Quantitative. Bilang parent company ng DeepSeek, nakamit ng quantitative fund na ito ang 53% return rate noong nakaraang taon, at higit $700 milyon (mga 5 bilyong RMB) na kita. Direktang ginamit ni Liang Wenfeng ang lumang perang ito para suportahan ang bagong pangarap ng "DeepSeek AGI". Sa ganitong modelo, napakalaya ng DeepSeek sa paggamit ng pera. 
Walang pakialam ang mga financiers.
Walang "malalaking kumpanya disease", maraming laboratoryo na nakakuha ng malaking pondo ang nasadlak sa papel na kayamanan at internal conflict, gaya na lang ng Thinking Machine Lab na sunod-sunod ang balitang resignation; pati na rin mga tsismis sa Meta AI laboratory ni Zuckerberg.
Nakatuon lang sa teknolohiya, dahil walang external valuation pressure, hindi kailangan ng DeepSeek magmadaling maglunsad ng all-in-one app para gumanda ang financial report, o sumabay sa multi-modal hype. Teknolohiya lang ang habol, hindi financial statement. Ang download ranking ng App Store ay life-and-death matter para sa mga startup na kailangang patunayan sa VC ang "daily active growth". Pero para sa laboratoryong may sagot lang sa AI development, hindi kulang sa pera at ayaw pa makontrol ng KPI, ang pagbaba ng market ranking ay maaaring siyang best protection nito para manatiling focused at hindi maingayan ng labas. Bukod pa rito, ayon sa ulat ng QuestMobile, hindi naman talaga "nahuhuli" ang influence ng DeepSeek Binago ang buhay, nakaapekto rin sa global AI arms race Kahit pa parang hindi alintana ng DeepSeek kung tayo ay pumili na ng ibang mas magandang AI app, hindi maikakaila na malaki ang naiambag nito sa bawat industriya nitong isang taon. Silicon Valley na "DeepSeek Shock" Noong umpisa, hindi lang magagamit na tool ang DeepSeek—naging trendsetter ito na nagbuwag ng high-threshold myth ng mga Silicon Valley giants gamit ang napaka-epektibo at murang paraan.
Bukod pa rito, ayon sa ulat ng QuestMobile, hindi naman talaga "nahuhuli" ang influence ng DeepSeek Binago ang buhay, nakaapekto rin sa global AI arms race Kahit pa parang hindi alintana ng DeepSeek kung tayo ay pumili na ng ibang mas magandang AI app, hindi maikakaila na malaki ang naiambag nito sa bawat industriya nitong isang taon. Silicon Valley na "DeepSeek Shock" Noong umpisa, hindi lang magagamit na tool ang DeepSeek—naging trendsetter ito na nagbuwag ng high-threshold myth ng mga Silicon Valley giants gamit ang napaka-epektibo at murang paraan.  Kung isang taon na ang nakalipas ay paramihan ng GPU at laki ng model parameters ang labanan sa AI, ang pagdating ni DeepSeek ay tuluyang nagbago ng laro. Sa OpenAI at internal team nito (The Prompt) na kamakailan ay naglabas ng year-end review, kinilala nilang Ang paglabas ng DeepSeek R1 ay nagdulot ng "matinding pagyanig (jolted)" sa AI race noon, inilarawan pa bilang "seismic shock". Patuloy na pinapatunayan ng DeepSeek na ang top-class na model capacity ay hindi kailangang itambak lang sa super mahal na computation. Ayon sa bagong analisis ng ICIS Intelligence Service Company, tuluyang binasag ng DeepSeek ang paniniwala na computation power lang ang magtatakda ng lahat. Pinapakita nitong kahit limitado ang chips, at napakaliit ng gastos, puwede pa ring mag-train ng modelong kayang tumapat sa pinakabest sa US.
Kung isang taon na ang nakalipas ay paramihan ng GPU at laki ng model parameters ang labanan sa AI, ang pagdating ni DeepSeek ay tuluyang nagbago ng laro. Sa OpenAI at internal team nito (The Prompt) na kamakailan ay naglabas ng year-end review, kinilala nilang Ang paglabas ng DeepSeek R1 ay nagdulot ng "matinding pagyanig (jolted)" sa AI race noon, inilarawan pa bilang "seismic shock". Patuloy na pinapatunayan ng DeepSeek na ang top-class na model capacity ay hindi kailangang itambak lang sa super mahal na computation. Ayon sa bagong analisis ng ICIS Intelligence Service Company, tuluyang binasag ng DeepSeek ang paniniwala na computation power lang ang magtatakda ng lahat. Pinapakita nitong kahit limitado ang chips, at napakaliit ng gastos, puwede pa ring mag-train ng modelong kayang tumapat sa pinakabest sa US.  Dahil dito, mula sa "gawa ng pinakamatalinong model" naging "ginawang mas efficient, mas mura, at mas madaling ideploy" na ang bagong AI global competition. "Alternative" growth sa Microsoft report Habang ang Silicon Valley giants ay nag-uunahan sa paid subscription users, nagsimulang mag-ugat si DeepSeek sa mga lugar na nakaligtaan ng giants. Sa Microsoft na inilabas na "2025 Global AI Popularization Report" noong isang linggo, tinukoy ang pag-angat ng DeepSeek bilang isa sa "pinakanakakagulat na development ng 2025". May interesting na data ang report:
Dahil dito, mula sa "gawa ng pinakamatalinong model" naging "ginawang mas efficient, mas mura, at mas madaling ideploy" na ang bagong AI global competition. "Alternative" growth sa Microsoft report Habang ang Silicon Valley giants ay nag-uunahan sa paid subscription users, nagsimulang mag-ugat si DeepSeek sa mga lugar na nakaligtaan ng giants. Sa Microsoft na inilabas na "2025 Global AI Popularization Report" noong isang linggo, tinukoy ang pag-angat ng DeepSeek bilang isa sa "pinakanakakagulat na development ng 2025". May interesting na data ang report:
Mataas ang paggamit sa Africa: Dahil sa free strategy at open source nature ng DeepSeek, nawala ang hadlang ng mahal na subscription at credit card. Ang usage nito sa Africa ay 2 hanggang 4 na beses na mas mataas kaysa ibang rehiyon.
Sinakop ang restricted markets: Sa mga rehiyong hindi maabot ng US tech giants o may limitadong serbisyo, halos si DeepSeek na lang ang option. May 89% market share ito sa China, 56% sa Belarus, at 49% sa Cuba. Kinilala rin ng Microsoft sa report na ang tagumpay ni DeepSeek ay nagpapakita na hindi lamang lakas ng model ang mahalaga, kundi sino ang kayang gamitin ito.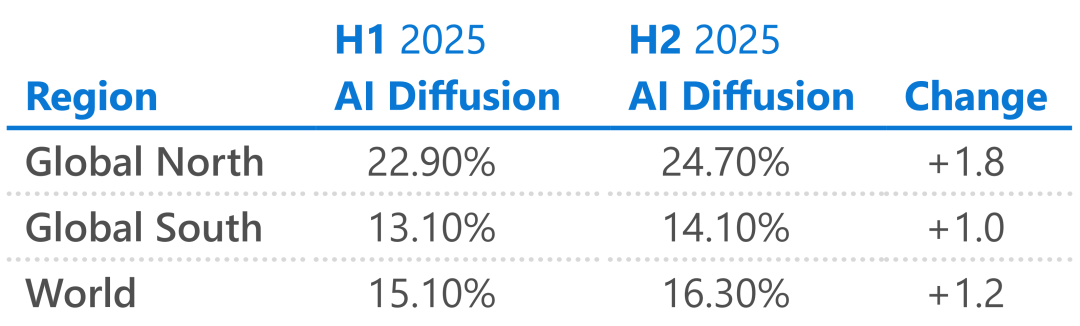 Ang susunod na bilyon na AI users ay maaaring hindi mula sa tradisyonal na tech hubs kundi mula sa mga lugar na sinasakop ni DeepSeek. Europa: Gusto rin namin ng DeepSeek Hindi lang Silicon Valley, kinikilala na rin sa buong Europa ang impluwensya ng DeepSeek. Palaging passive user ng US AI ang Europe, kahit may sariling modelong Mistral, hindi ito sumisikat. Sa tagumpay ng DeepSeek, nakita ng mga Europeo ang bagong landas—kung nagawa ng isang resource-limited na Chinese lab, bakit hindi magagawa ng Europe?
Ang susunod na bilyon na AI users ay maaaring hindi mula sa tradisyonal na tech hubs kundi mula sa mga lugar na sinasakop ni DeepSeek. Europa: Gusto rin namin ng DeepSeek Hindi lang Silicon Valley, kinikilala na rin sa buong Europa ang impluwensya ng DeepSeek. Palaging passive user ng US AI ang Europe, kahit may sariling modelong Mistral, hindi ito sumisikat. Sa tagumpay ng DeepSeek, nakita ng mga Europeo ang bagong landas—kung nagawa ng isang resource-limited na Chinese lab, bakit hindi magagawa ng Europe?  Ayon sa Wired magazine kamakailan, may kumpetisyon na ngayon sa Europe para gumawa ng "European version ng DeepSeek". Maraming developer sa Europe ang nagsisimula ng open source large models, at isa na rito ang proyektong SOOFI na hayagang nagsabing "Kami ang magiging DeepSeek ng Europe." Ang epekto ng DeepSeek nitong nakaraang taon ay nagpalala ng anxiety ng Europe tungkol sa "AI sovereignty". Napagtanto nila ang panganib ng sobrang pag-asa sa US closed-source models, at ang efficient, open source mode ng DeepSeek ang siyang kailangan nilang tularan. Tungkol sa V4, ito ang mga dapat abangan Patuloy ang epekto—kung ang R1 ng isang taon ang demo ni DeepSeek sa AI industry, ang paparating na V4 kaya ay muling magpakita ng kakaibang diskarte? Batay sa ilang leaks at bagong technical papers, ito ang mga pangunahing signal tungkol sa V4 na dapat abangan. 1. Pagkakabunyag ng bagong model na MODEL1
Ayon sa Wired magazine kamakailan, may kumpetisyon na ngayon sa Europe para gumawa ng "European version ng DeepSeek". Maraming developer sa Europe ang nagsisimula ng open source large models, at isa na rito ang proyektong SOOFI na hayagang nagsabing "Kami ang magiging DeepSeek ng Europe." Ang epekto ng DeepSeek nitong nakaraang taon ay nagpalala ng anxiety ng Europe tungkol sa "AI sovereignty". Napagtanto nila ang panganib ng sobrang pag-asa sa US closed-source models, at ang efficient, open source mode ng DeepSeek ang siyang kailangan nilang tularan. Tungkol sa V4, ito ang mga dapat abangan Patuloy ang epekto—kung ang R1 ng isang taon ang demo ni DeepSeek sa AI industry, ang paparating na V4 kaya ay muling magpakita ng kakaibang diskarte? Batay sa ilang leaks at bagong technical papers, ito ang mga pangunahing signal tungkol sa V4 na dapat abangan. 1. Pagkakabunyag ng bagong model na MODEL1
Sa anibersaryo ng DeepSeek-R1, hindi sinasadyang nailabas sa official GitHub repository ang "MODEL1"—isang bagong model. Sa code logic structure, hiwalay at independent branch ang "MODEL1" mula sa "V32" (DeepSeek-V3.2), na ibig sabihin, hindi sila shared ng parameters o core architecture—bagong technical path ito. Batay sa leaks at code snippets, ito ang possible technical characteristics ng "MODEL1":
Batay sa leaks at code snippets, ito ang possible technical characteristics ng "MODEL1":  3. Core capability: Code at super long context Ngayong parang halos pare-pareho na ang general chat, mas pinili ng V4 na sumugal sa productivity-level code capability. Ayon sa sources malapit sa DeepSeek, hindi lang tumigil si V4 sa napakagandang performance ng V3.2 sa benchmarks—sa internal tests, nalampasan na niya ang Claude ng Anthropic at GPT series ng OpenAI sa code generation at processing.
3. Core capability: Code at super long context Ngayong parang halos pare-pareho na ang general chat, mas pinili ng V4 na sumugal sa productivity-level code capability. Ayon sa sources malapit sa DeepSeek, hindi lang tumigil si V4 sa napakagandang performance ng V3.2 sa benchmarks—sa internal tests, nalampasan na niya ang Claude ng Anthropic at GPT series ng OpenAI sa code generation at processing. 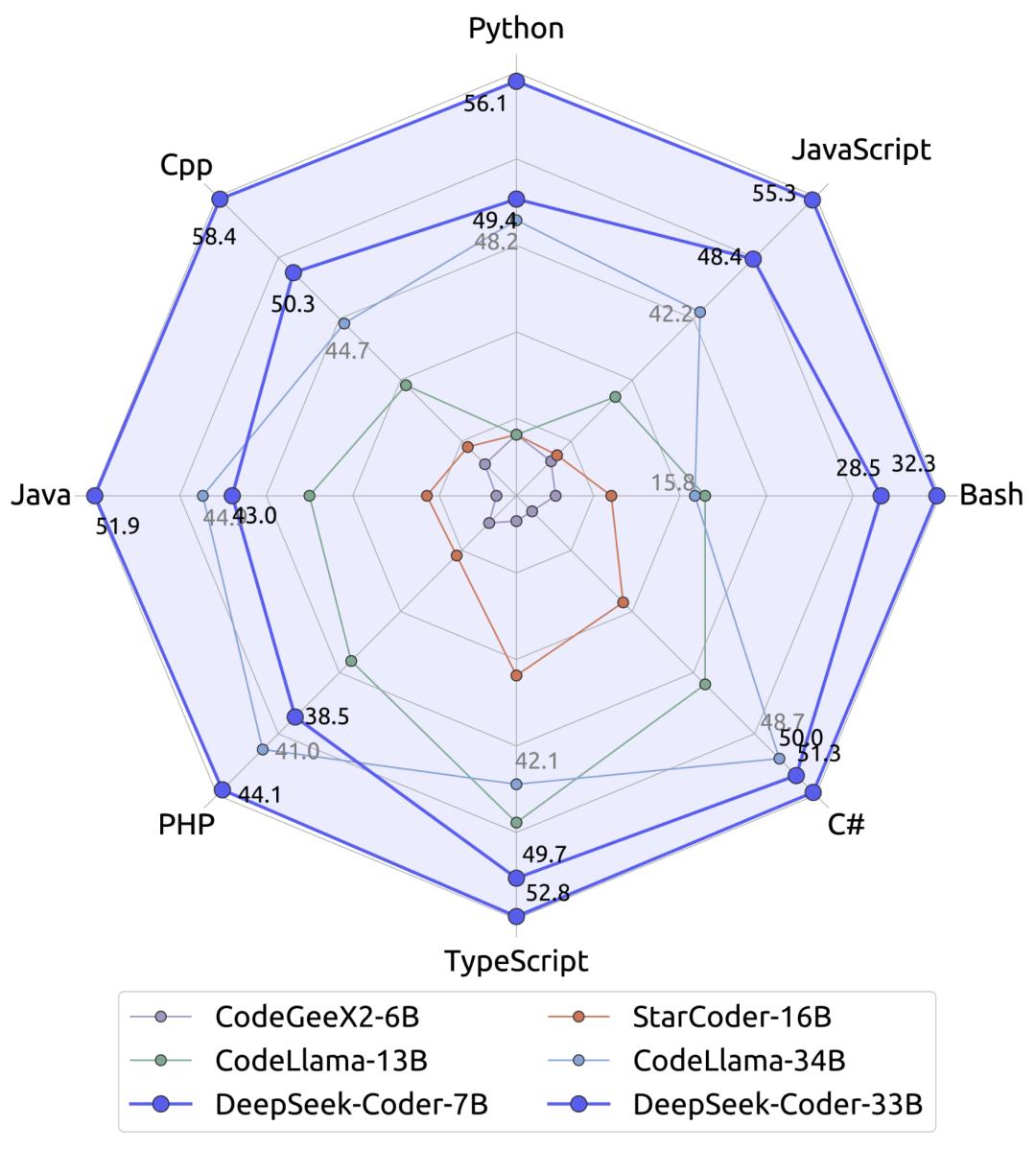 Mas mahalaga pa, tinatarget ng V4 na solusyunan ang malaking pain point ng programming AI—ang pag-handle ng "super long code prompts". Ibig sabihin, hindi lang siya simpleng assistant na gagawa ng ilang linya ng script, kundi may kakayahan nang maintindihan ang complex na software project at malaking codebase. Para magawa ito, in-improve din ng V4 ang training process para siguraduhin na kahit malaki ang data pattern, hindi magde-degrade ang model habang lumalalim ang training. 4. Key technology: Engram Higit pa sa V4 model mismo,mas dapat bigyang pansin ang bagong joint paper ng DeepSeek at Peking University na inilabas noong isang linggo. Ipinapaliwanag ng paper na ang tunay na trump card ng DeepSeek para makalusot kahit kulang sa computing ay isang bagong teknolohiya na tinatawag na "Engram (trace/conditional memory)".
Mas mahalaga pa, tinatarget ng V4 na solusyunan ang malaking pain point ng programming AI—ang pag-handle ng "super long code prompts". Ibig sabihin, hindi lang siya simpleng assistant na gagawa ng ilang linya ng script, kundi may kakayahan nang maintindihan ang complex na software project at malaking codebase. Para magawa ito, in-improve din ng V4 ang training process para siguraduhin na kahit malaki ang data pattern, hindi magde-degrade ang model habang lumalalim ang training. 4. Key technology: Engram Higit pa sa V4 model mismo,mas dapat bigyang pansin ang bagong joint paper ng DeepSeek at Peking University na inilabas noong isang linggo. Ipinapaliwanag ng paper na ang tunay na trump card ng DeepSeek para makalusot kahit kulang sa computing ay isang bagong teknolohiya na tinatawag na "Engram (trace/conditional memory)". 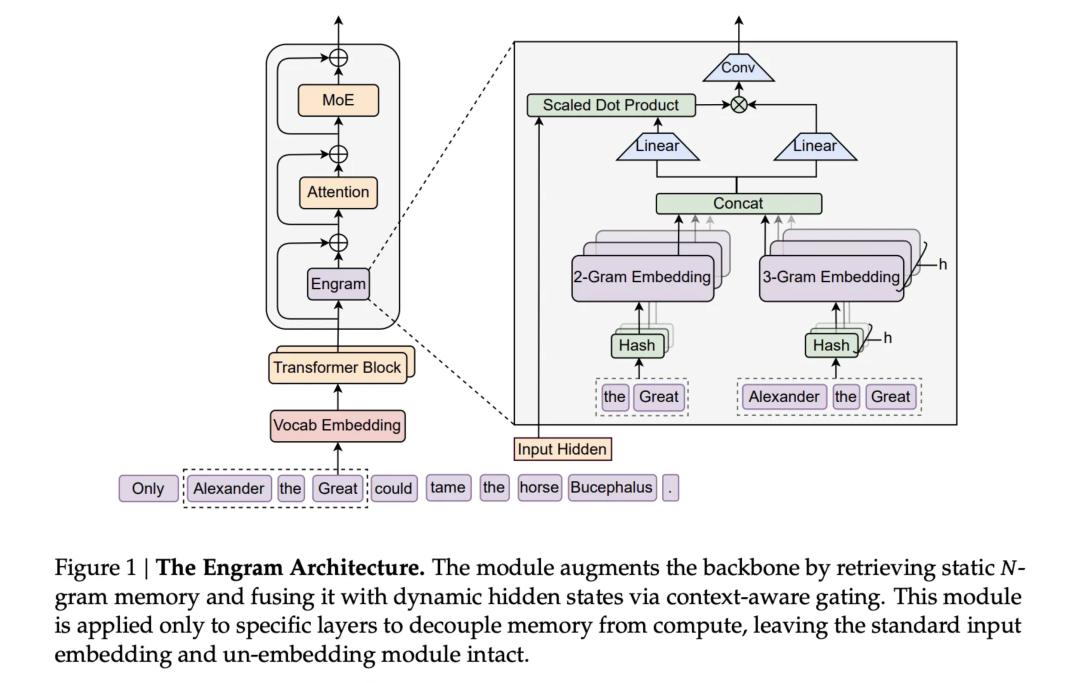 Ang HBM (high bandwidth memory) ay isa sa mga susi ng global AI computing power competition. Habang ang ibang players ay nag-iipon ng H100 GPU para sa memory, ibang landas ang tinatahak ng DeepSeek.
Ang HBM (high bandwidth memory) ay isa sa mga susi ng global AI computing power competition. Habang ang ibang players ay nag-iipon ng H100 GPU para sa memory, ibang landas ang tinatahak ng DeepSeek.
Decoupling ng computation at memory: Karaniwan, kailangan ng mga model na gumastos ng mahal na computation para lang mag-retrieve ng basic info. Sa Engram, mabilis na makukuha ng model ang info nang hindi inuulit ang computation.
Ang natipid na computation ay nakalaan para sa mas mahirap na reasoning tasks.
Ayon sa researchers, kaya nitong lampasan ang limitasyon ng VRAM at suportahan ang aggressive parameter expansion, kaya posibleng mas lalaki pa ang model. Sa panahon ng kakulangan ng GPU, parang sinasabi rin ng DeepSeek sa kanilang paper na hindi sila umaasa lang sa hardware stacking. Ang evolution ng DeepSeek nitong isang taon ay literal na paggamit ng counter-intuitive na paraan para lutasin ang mga common sense problem ng AI industry. Kumita siya ng 5 bilyon sa isang taon, sapat para mag-train ng libo-libong DeepSeek R1, pero hindi siya sumasabay sa compute power arms race o GPU wars, walang balitang mag-i-IPO o maghahanap ng pondo, bagkus nagreresearch pa kung paano papalitan ang HBM ng mas murang memory. Nitong nakaraang taon, halos tuluyan na niyang binitiwan ang all-in-one model traffic. Habang ang ibang model makers ay may malaking update buwan-buwan at maliit na update linggo-linggo, si DeepSeek ay buong focus sa inference model, paulit-ulit na pinapabuti ang inference model papers. Sa maikling panahon, mali lahat ang mga choice na ito—kung walang pondo, paano makakalaban sa resource ng OpenAI? Kung hindi gagawa ng multi-modal all-in-one app, paano mapapanatili ang users? Kung hindi mag-stack ng compute, paano makakagawa ng pinakamalakas na model?
Sa panahon ng kakulangan ng GPU, parang sinasabi rin ng DeepSeek sa kanilang paper na hindi sila umaasa lang sa hardware stacking. Ang evolution ng DeepSeek nitong isang taon ay literal na paggamit ng counter-intuitive na paraan para lutasin ang mga common sense problem ng AI industry. Kumita siya ng 5 bilyon sa isang taon, sapat para mag-train ng libo-libong DeepSeek R1, pero hindi siya sumasabay sa compute power arms race o GPU wars, walang balitang mag-i-IPO o maghahanap ng pondo, bagkus nagreresearch pa kung paano papalitan ang HBM ng mas murang memory. Nitong nakaraang taon, halos tuluyan na niyang binitiwan ang all-in-one model traffic. Habang ang ibang model makers ay may malaking update buwan-buwan at maliit na update linggo-linggo, si DeepSeek ay buong focus sa inference model, paulit-ulit na pinapabuti ang inference model papers. Sa maikling panahon, mali lahat ang mga choice na ito—kung walang pondo, paano makakalaban sa resource ng OpenAI? Kung hindi gagawa ng multi-modal all-in-one app, paano mapapanatili ang users? Kung hindi mag-stack ng compute, paano makakagawa ng pinakamalakas na model?  Pero kung pahahabain ang timeline, posible ngang ang mga "maling" desisyon na ito ang naglalatag ng daan para sa DeepSeek V4 at R2. Iyan ang tunay na kulay ng DeepSeek—habang ang lahat ay nagpapaligsahan sa resources, nakatutok siya sa efficiency; habang ang lahat ay humahabol sa commercialization, siya ay naghahanap ng technology edge. Magpapatuloy kaya ito sa V4, o magko-compromise na sa "common sense"? Baka sa susunod na linggo na natin malalaman ang sagot. Pero ang sigurado, sa AI industry, minsan ang kontra sa common sense ang siyang pinakamalaking common sense. Sa susunod, DeepSeek moment pa rin.
Pero kung pahahabain ang timeline, posible ngang ang mga "maling" desisyon na ito ang naglalatag ng daan para sa DeepSeek V4 at R2. Iyan ang tunay na kulay ng DeepSeek—habang ang lahat ay nagpapaligsahan sa resources, nakatutok siya sa efficiency; habang ang lahat ay humahabol sa commercialization, siya ay naghahanap ng technology edge. Magpapatuloy kaya ito sa V4, o magko-compromise na sa "common sense"? Baka sa susunod na linggo na natin malalaman ang sagot. Pero ang sigurado, sa AI industry, minsan ang kontra sa common sense ang siyang pinakamalaking common sense. Sa susunod, DeepSeek moment pa rin.
Lumabas ang DeepSeek dala ang R1 noong eksaktong isang taon na ang nakalipas (2025.1.20), at agad nitong nakuha ang atensyon ng buong mundo. Noong panahong iyon, para lang magamit ng maayos ang DeepSeek, sinubukan kong hanapin lahat ng self-deployment na tutorial, at nag-download pa ako ng iba’t ibang app na may pangakong "XX - DeepSeek Buong Lakas na Bersyon". Pagkatapos ng isang taon, sa totoo lang, madalang ko na lang buksan ang DeepSeek. Kayang mag-search at mag-generate ng larawan si Doubao, nakakonekta na si Qianwen sa Taobao at Gaode, may real-time voice chat at content ecosystem ng WeChat Official Account si Yuanbao; di na rin mabanggit ang overseas na ChatGPT, Gemini at iba pang SOTA na AI model products. Habang patuloy na humahaba ang listahan ng mga function ng mga all-in-one AI assistant na ito, tapat kong tinanong ang sarili ko: "Kung may mas maginhawa, bakit pa ako magtitiyaga sa DeepSeek?" Kaya naman, mula sa unang screen ng phone ko, lumipat na sa pangalawang screen ang DeepSeek, mula sa araw-araw na ginagamit, naging paminsan-minsan na lang kung maaalala. Tiningnan ko ang ranking ng App Store, at tila hindi lang ako ang nakaramdam ng "paglamig ng damdamin" na ito. Ang top 3 sa listahan ng libreng apps ay sinakop na ng "Big Three" ng mga lokal na internet giants, at ang dating namamayani na DeepSeek ay tahimik na bumaba na lang sa ika-pitong pwesto. Sa hanay ng mga kakompetensya na halos isulat na sa mukha ang "all-in-one, multi-modal, AI search", tila naiiba si DeepSeek—51.7 MB na napakasimpleng installation package, hindi habol ang trending, hindi nagpapaligsahan sa marketing, at ni wala pang visual reasoning at multi-modal na features. Pero dito nagiging mas kapana-panabik. Sa unang tingin, parang "nahuhuli" na siya, pero sa katotohanan, ang DeepSeek pa rin ang pangunahing modelong ginagamit ng karamihan sa mga platform. Nang sinubukan kong buuin ang mga naging hakbang ng DeepSeek nitong nakaraang taon, at ilipat ang tingin ko mula sa simpleng download ranking papunta sa global AI development, sinubukang intindihin kung bakit ito kalmado at ano ang bagong aabangan sa V4, Nalaman ko na ang "ikapitong pwesto" na ito, para sa DeepSeek, ay walang saysay—lagi siyang "multo" na hindi mapakali ang mga higante sa industriya. Nahuhuli? May sariling ritmo ang DeepSeek Habang ang mga AI giants sa buong mundo ay pinipilit ng kapital, ginagamit ang commercialization para sa kita, nabubuhay si DeepSeek na parang nag-iisang free agent. Tingnan ang mga kakompetensya nito, mula sa bagong Hong Kong-listed na Zhipu at MiniMax, hanggang sa overseas na OpenAI at Anthropic na nagiging aggressive sa investment. Para mapanatili ang mahal na kompetisyon sa computing power, hindi na rin kinaya ni Musk ang tukso ng kapital—kakakuha lang niya ng $20 bilyon na pondo para sa xAI ilang araw na ang nakalipas. Ngunit hanggang ngayon, nananatili ang DeepSeek sa "zero external financing". Sa taunang top 100 private equity list, ayon sa average returns ng kumpanya, nasa ikapitong pwesto ang Huansquare Quantitative,pangalawa pagdating sa scale na higit sa sampung bilyon Sa panahon ngayon na lahat nagmamadaling mag-cash out, magpakitang gilas sa investors, ang lakas ng loob ng DeepSeek na "mahuli" ay dahil sa "super money machine" sa likod niya—ang Huansquare Quantitative. Bilang parent company ng DeepSeek, nakamit ng quantitative fund na ito ang 53% return rate noong nakaraang taon, at higit $700 milyon (mga 5 bilyong RMB) na kita. Direktang ginamit ni Liang Wenfeng ang lumang perang ito para suportahan ang bagong pangarap ng "DeepSeek AGI". Sa ganitong modelo, napakalaya ng DeepSeek sa paggamit ng pera. Walang pakialam ang mga financiers.
Walang "malalaking kumpanya disease", maraming laboratoryo na nakakuha ng malaking pondo ang nasadlak sa papel na kayamanan at internal conflict, gaya na lang ng Thinking Machine Lab na sunod-sunod ang balitang resignation; pati na rin mga tsismis sa Meta AI laboratory ni Zuckerberg.
Nakatuon lang sa teknolohiya, dahil walang external valuation pressure, hindi kailangan ng DeepSeek magmadaling maglunsad ng all-in-one app para gumanda ang financial report, o sumabay sa multi-modal hype. Teknolohiya lang ang habol, hindi financial statement. Ang download ranking ng App Store ay life-and-death matter para sa mga startup na kailangang patunayan sa VC ang "daily active growth". Pero para sa laboratoryong may sagot lang sa AI development, hindi kulang sa pera at ayaw pa makontrol ng KPI, ang pagbaba ng market ranking ay maaaring siyang best protection nito para manatiling focused at hindi maingayan ng labas.
Bukod pa rito, ayon sa ulat ng QuestMobile, hindi naman talaga "nahuhuli" ang influence ng DeepSeek Binago ang buhay, nakaapekto rin sa global AI arms race Kahit pa parang hindi alintana ng DeepSeek kung tayo ay pumili na ng ibang mas magandang AI app, hindi maikakaila na malaki ang naiambag nito sa bawat industriya nitong isang taon. Silicon Valley na "DeepSeek Shock" Noong umpisa, hindi lang magagamit na tool ang DeepSeek—naging trendsetter ito na nagbuwag ng high-threshold myth ng mga Silicon Valley giants gamit ang napaka-epektibo at murang paraan. Kung isang taon na ang nakalipas ay paramihan ng GPU at laki ng model parameters ang labanan sa AI, ang pagdating ni DeepSeek ay tuluyang nagbago ng laro. Sa OpenAI at internal team nito (The Prompt) na kamakailan ay naglabas ng year-end review, kinilala nilang Ang paglabas ng DeepSeek R1 ay nagdulot ng "matinding pagyanig (jolted)" sa AI race noon, inilarawan pa bilang "seismic shock". Patuloy na pinapatunayan ng DeepSeek na ang top-class na model capacity ay hindi kailangang itambak lang sa super mahal na computation. Ayon sa bagong analisis ng ICIS Intelligence Service Company, tuluyang binasag ng DeepSeek ang paniniwala na computation power lang ang magtatakda ng lahat. Pinapakita nitong kahit limitado ang chips, at napakaliit ng gastos, puwede pa ring mag-train ng modelong kayang tumapat sa pinakabest sa US. Dahil dito, mula sa "gawa ng pinakamatalinong model" naging "ginawang mas efficient, mas mura, at mas madaling ideploy" na ang bagong AI global competition. "Alternative" growth sa Microsoft report Habang ang Silicon Valley giants ay nag-uunahan sa paid subscription users, nagsimulang mag-ugat si DeepSeek sa mga lugar na nakaligtaan ng giants. Sa Microsoft na inilabas na "2025 Global AI Popularization Report" noong isang linggo, tinukoy ang pag-angat ng DeepSeek bilang isa sa "pinakanakakagulat na development ng 2025". May interesting na data ang report: Mataas ang paggamit sa Africa: Dahil sa free strategy at open source nature ng DeepSeek, nawala ang hadlang ng mahal na subscription at credit card. Ang usage nito sa Africa ay 2 hanggang 4 na beses na mas mataas kaysa ibang rehiyon.
Sinakop ang restricted markets: Sa mga rehiyong hindi maabot ng US tech giants o may limitadong serbisyo, halos si DeepSeek na lang ang option. May 89% market share ito sa China, 56% sa Belarus, at 49% sa Cuba. Kinilala rin ng Microsoft sa report na ang tagumpay ni DeepSeek ay nagpapakita na hindi lamang lakas ng model ang mahalaga, kundi sino ang kayang gamitin ito.
Ang susunod na bilyon na AI users ay maaaring hindi mula sa tradisyonal na tech hubs kundi mula sa mga lugar na sinasakop ni DeepSeek. Europa: Gusto rin namin ng DeepSeek Hindi lang Silicon Valley, kinikilala na rin sa buong Europa ang impluwensya ng DeepSeek. Palaging passive user ng US AI ang Europe, kahit may sariling modelong Mistral, hindi ito sumisikat. Sa tagumpay ng DeepSeek, nakita ng mga Europeo ang bagong landas—kung nagawa ng isang resource-limited na Chinese lab, bakit hindi magagawa ng Europe? Ayon sa Wired magazine kamakailan, may kumpetisyon na ngayon sa Europe para gumawa ng "European version ng DeepSeek". Maraming developer sa Europe ang nagsisimula ng open source large models, at isa na rito ang proyektong SOOFI na hayagang nagsabing "Kami ang magiging DeepSeek ng Europe." Ang epekto ng DeepSeek nitong nakaraang taon ay nagpalala ng anxiety ng Europe tungkol sa "AI sovereignty". Napagtanto nila ang panganib ng sobrang pag-asa sa US closed-source models, at ang efficient, open source mode ng DeepSeek ang siyang kailangan nilang tularan. Tungkol sa V4, ito ang mga dapat abangan Patuloy ang epekto—kung ang R1 ng isang taon ang demo ni DeepSeek sa AI industry, ang paparating na V4 kaya ay muling magpakita ng kakaibang diskarte? Batay sa ilang leaks at bagong technical papers, ito ang mga pangunahing signal tungkol sa V4 na dapat abangan. 1. Pagkakabunyag ng bagong model na MODEL1 Sa anibersaryo ng DeepSeek-R1, hindi sinasadyang nailabas sa official GitHub repository ang "MODEL1"—isang bagong model. Sa code logic structure, hiwalay at independent branch ang "MODEL1" mula sa "V32" (DeepSeek-V3.2), na ibig sabihin, hindi sila shared ng parameters o core architecture—bagong technical path ito.
Batay sa leaks at code snippets, ito ang possible technical characteristics ng "MODEL1": - May totally ibang KV Cache layout strategy at bagong mechanism sa sparsity handling.
- Sa FP8 decoding path, maraming memory optimization—maaaring mas efficient at mas kaunti ang VRAM na kailangan.
- Ayon sa leaks, lampas na sa Claude at GPT series ang performance ng V4 sa code, at kaya nitong mag-handle ng complex na project architecture at malalaking codebase.
3. Core capability: Code at super long context Ngayong parang halos pare-pareho na ang general chat, mas pinili ng V4 na sumugal sa productivity-level code capability. Ayon sa sources malapit sa DeepSeek, hindi lang tumigil si V4 sa napakagandang performance ng V3.2 sa benchmarks—sa internal tests, nalampasan na niya ang Claude ng Anthropic at GPT series ng OpenAI sa code generation at processing. Mas mahalaga pa, tinatarget ng V4 na solusyunan ang malaking pain point ng programming AI—ang pag-handle ng "super long code prompts". Ibig sabihin, hindi lang siya simpleng assistant na gagawa ng ilang linya ng script, kundi may kakayahan nang maintindihan ang complex na software project at malaking codebase. Para magawa ito, in-improve din ng V4 ang training process para siguraduhin na kahit malaki ang data pattern, hindi magde-degrade ang model habang lumalalim ang training. 4. Key technology: Engram Higit pa sa V4 model mismo,mas dapat bigyang pansin ang bagong joint paper ng DeepSeek at Peking University na inilabas noong isang linggo. Ipinapaliwanag ng paper na ang tunay na trump card ng DeepSeek para makalusot kahit kulang sa computing ay isang bagong teknolohiya na tinatawag na "Engram (trace/conditional memory)". Ang HBM (high bandwidth memory) ay isa sa mga susi ng global AI computing power competition. Habang ang ibang players ay nag-iipon ng H100 GPU para sa memory, ibang landas ang tinatahak ng DeepSeek. Decoupling ng computation at memory: Karaniwan, kailangan ng mga model na gumastos ng mahal na computation para lang mag-retrieve ng basic info. Sa Engram, mabilis na makukuha ng model ang info nang hindi inuulit ang computation.
Ang natipid na computation ay nakalaan para sa mas mahirap na reasoning tasks.
Ayon sa researchers, kaya nitong lampasan ang limitasyon ng VRAM at suportahan ang aggressive parameter expansion, kaya posibleng mas lalaki pa ang model.
Sa panahon ng kakulangan ng GPU, parang sinasabi rin ng DeepSeek sa kanilang paper na hindi sila umaasa lang sa hardware stacking. Ang evolution ng DeepSeek nitong isang taon ay literal na paggamit ng counter-intuitive na paraan para lutasin ang mga common sense problem ng AI industry. Kumita siya ng 5 bilyon sa isang taon, sapat para mag-train ng libo-libong DeepSeek R1, pero hindi siya sumasabay sa compute power arms race o GPU wars, walang balitang mag-i-IPO o maghahanap ng pondo, bagkus nagreresearch pa kung paano papalitan ang HBM ng mas murang memory. Nitong nakaraang taon, halos tuluyan na niyang binitiwan ang all-in-one model traffic. Habang ang ibang model makers ay may malaking update buwan-buwan at maliit na update linggo-linggo, si DeepSeek ay buong focus sa inference model, paulit-ulit na pinapabuti ang inference model papers. Sa maikling panahon, mali lahat ang mga choice na ito—kung walang pondo, paano makakalaban sa resource ng OpenAI? Kung hindi gagawa ng multi-modal all-in-one app, paano mapapanatili ang users? Kung hindi mag-stack ng compute, paano makakagawa ng pinakamalakas na model? Pero kung pahahabain ang timeline, posible ngang ang mga "maling" desisyon na ito ang naglalatag ng daan para sa DeepSeek V4 at R2. Iyan ang tunay na kulay ng DeepSeek—habang ang lahat ay nagpapaligsahan sa resources, nakatutok siya sa efficiency; habang ang lahat ay humahabol sa commercialization, siya ay naghahanap ng technology edge. Magpapatuloy kaya ito sa V4, o magko-compromise na sa "common sense"? Baka sa susunod na linggo na natin malalaman ang sagot. Pero ang sigurado, sa AI industry, minsan ang kontra sa common sense ang siyang pinakamalaking common sense. Sa susunod, DeepSeek moment pa rin. 
0
0
Disclaimer: Ang nilalaman ng artikulong ito ay sumasalamin lamang sa opinyon ng author at hindi kumakatawan sa platform sa anumang kapasidad. Ang artikulong ito ay hindi nilayon na magsilbi bilang isang sanggunian para sa paggawa ng mga desisyon sa investment.
PoolX: Naka-lock para sa mga bagong token.
Hanggang 12%. Palaging naka-on, laging may airdrop.
Mag Locked na ngayon!
Baka magustuhan mo rin
‘Bull trap’ ng Bitcoin ang nabubuo habang pumapasok ang bear market sa gitnang yugto: Willy Woo
Cointelegraph•2026/03/08 08:11
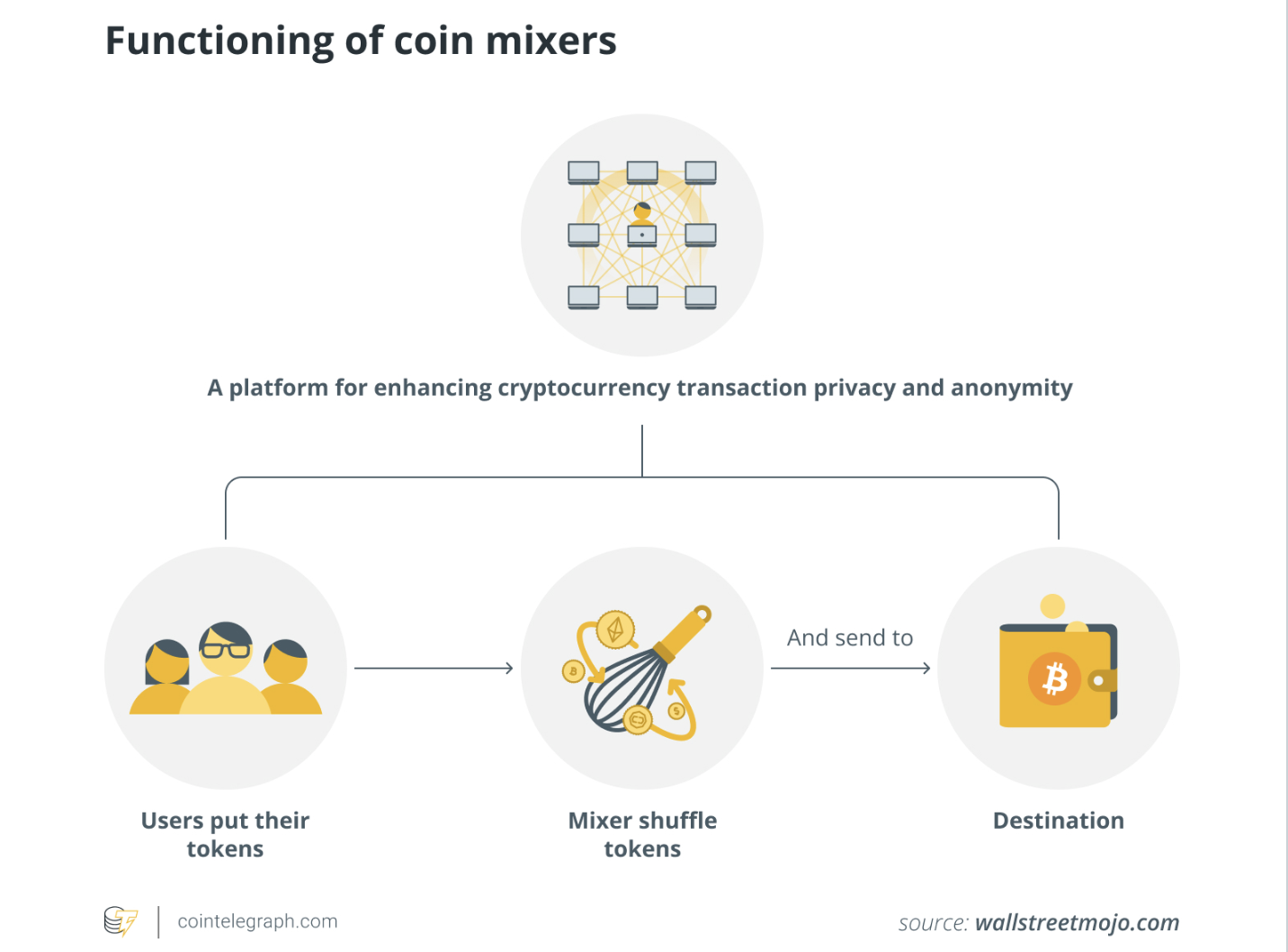
Kinilala ng ulat ng US Treasury ang mga lehitimong gamit ng crypto mixers
Cointelegraph•2026/03/08 08:08
Lumago ang sektor ng AI sa $14.4B ngunit humina ang Bittensor – Babalik ba ang TAO sa $165?
AMBCrypto•2026/03/08 08:03
Trending na balita
Higit paMga presyo ng crypto
Higit paBitcoin
BTC
$67,263.47
-1.05%
Ethereum
ETH
$1,951.84
-1.71%
Tether USDt
USDT
$1.0000
+0.00%
BNB
BNB
$618.73
-1.53%
XRP
XRP
$1.36
-0.83%
USDC
USDC
$0.9999
+0.00%
Solana
SOL
$82.74
-1.89%
TRON
TRX
$0.2865
+0.98%
Dogecoin
DOGE
$0.08911
-1.65%
Cardano
ADA
$0.2513
-2.83%
Paano magbenta ng PI
Inililista ng Bitget ang PI – Buy or sell ng PI nang mabilis sa Bitget!
Trade na ngayon
Hindi pa Bitgetter?Isang welcome pack na nagkakahalaga ng 6200 USDT para sa mga bagong Bitgetters!
Mag-sign up na